Using a Windows service in your .NET project part 8: Windows Service body part 2
October 30, 2014 3 Comments
Introduction
In the previous post of this series we started adding some code to the Windows service. We also implemented a simplified logging system to be able to track what’s happening within the service. In this post we’ll start adding code to actually run the HTTP jobs inserted in MongoDb.
So open the demo application in VS and let’s start.
HttpJobRunner process
We established before that HttpJobRunner will need an IHttpJobService to retrieve the new jobs and an IHttpJobExecutionService to run them. Open HttpJobRunner.cs and add the following private fields:
private readonly IHttpJobService _httpJobService; private readonly IHttpJobExecutionService _httpJobExecutionService;
Extend the constructor as follows:
public HttpJobRunner(ILoggingService loggingService, IHttpJobService httpJobService, IHttpJobExecutionService httpJoExecutionService)
{
InitializeComponent();
if (loggingService == null) throw new ArgumentNullException("LoggingService");
if (httpJobService == null) throw new ArgumentNullException("HttpJobService");
if (httpJobExecutionService == null) throw new ArgumentNullException("HttpJobExecutionService");
_loggingService = loggingService;
_httpJobService = httpJobService;
_httpJobExecutionService = httpJobExecutionService;
TaskScheduler.UnobservedTaskException += TaskScheduler_UnobservedTaskException;
}
Program.cs in Demo.HttpJobRunner will start complaining of course. Open that file and extend its body to the following:
static class Program
{
static void Main()
{
ServiceBase[] ServicesToRun;
IHttpJobService httpJobService = BuildHttpJobService();
IHttpJobExecutionService httpJobExecutionService = BuildHttpJobExecutionService(httpJobService);
ServicesToRun = new ServiceBase[]
{
new HttpJobRunner(new FileBasedLoggingService(@"c:\logging\log.txt"), httpJobService, httpJobExecutionService)
};
ServiceBase.Run(ServicesToRun);
}
private static IHttpJobService BuildHttpJobService()
{
IConfigurationRepository configurationRepository = new ConfigFileConfigurationRepository();
IDatabaseConnectionSettingsService dbConnectionSettingsService = new HttpJobDatabaseConnectionService(configurationRepository);
IJobRepository jobRepository = new JobRepository(dbConnectionSettingsService);
IHttpJobService httpJobService = new HttpJobService(jobRepository);
return httpJobService;
}
private static IHttpJobExecutionService BuildHttpJobExecutionService(IHttpJobService httpJobService)
{
IHttpJobExecutionService httpJobExecutionService = new HttpJobExecutionService(httpJobService, new HttpJobUrlService(new HttpClientService()));
return httpJobExecutionService;
}
}
You’ll need to add a reference to all other projects in the solution from Demo.HttpJobRunner for this code to compile. We do nothing else but declare the concrete implementations of the abstractions in the entry point of the Windows service application.
HttpJobRunner has all the dependencies it needs now so we can continue. Well, almost. recall that we saved the connection string and the HttpJobs table name in app.config of the Console application. Check the files available for the Windows service project. There should be another app.config. When we deploy the Windows service then it will consult its own app.config, which is totally independent of the app.config of ConsoleConsumer. It won’t magically have access to the configuration file of the Console app. This means that we need to add the same settings to HttpJobRunner.app.config too. Copy the settings so that the Windows service app.config looks as follows:
<?xml version="1.0" encoding="utf-8" ?>
<configuration>
<connectionStrings>
<add name="HttpJobsConnectionString" connectionString="mongodb://localhost"/>
</connectionStrings>
<appSettings>
<add key="HttpJobsDatabaseName" value="HttpJobsDatabase"/>
</appSettings>
<startup>
<supportedRuntime version="v4.0" sku=".NETFramework,Version=v4.5" />
</startup>
</configuration>
The plan for the job execution process in the service is the following:
- Check the database for new jobs periodically
- If new jobs are found then log them and start running them on a different thread
- Log the result of the job
It’s important to start a new thread for each new job otherwise the job process will block all other code, including checking the database for new jobs. This way the service will be able to execute multiple jobs simultaneously.
We can instruct the Windows service to carry out a certain action using the Timer object in the System.Timers namespace. Add the following private field to the field list of HttpJobRunner:
private readonly Timer _jobCollectionTimer;
…and add the following code into the HttpJobRunner constructor to initialise the timer and attach an event listener to the Timer.Elapsed event:
_jobCollectionTimer = new Timer(10000); _jobCollectionTimer.Elapsed += _jobCollectionTimer_Elapsed;
…where _jobCollectionTimer_Elapsed was generated by Visual Studio and looks like this by default:
void _jobCollectionTimer_Elapsed(object sender, ElapsedEventArgs e)
{
throw new NotImplementedException();
}
This handler is called every 10 seconds, i.e. 10000 milliseconds we specified in the Timer’s constructor. Remove the “throw new…” bit from the handler body and add the “async” keyword in front of “void”:
async void _jobCollectionTimer_Elapsed(object sender, ElapsedEventArgs e)
We’ll have an awaitable asynchronous method call within the handler body hence the need for the async keyword.
We need to start the Timer as well. Add the following code…
_jobCollectionTimer.Start();
…to 3 overridden Windows service events:
- OnStart
- OnContinue
- OnPause
Here’s the body of the _jobCollectionTimer_Elapsed handler:
async void _jobCollectionTimer_Elapsed(object sender, ElapsedEventArgs e)
{
try
{
GetHttpJobsResponse getAllNewHttpJobsResponse = _httpJobService.GetNewHttpJobs();
if (getAllNewHttpJobsResponse.OperationException != null) throw getAllNewHttpJobsResponse.OperationException;
IEnumerable<HttpJob> newJobs = getAllNewHttpJobsResponse.HttpJobs;
if (newJobs.Count() > 0)
{
LogNewJobs(newJobs);
foreach (HttpJob httpJob in newJobs)
{
await Task.Factory.StartNew(async () => await RunSingleHttpJob(httpJob));
}
}
}
catch (Exception ex)
{
LogException(ex);
}
}
…and here come the private helper methods:
private async Task RunSingleHttpJob(HttpJob httpJob)
{
LogStartOfNewJob(httpJob);
try
{
await _httpJobExecutionService.Execute(httpJob);
}
catch (Exception ex)
{
LogException(ex);
}
LogEndOfNewJob(httpJob);
}
private void LogStartOfNewJob(HttpJob newJob)
{
StringBuilder sb = new StringBuilder();
sb.Append("About to start job ").Append(newJob.CorrelationId);
_loggingService.LogInfo(this, sb.ToString());
}
private void LogEndOfNewJob(HttpJob newJob)
{
StringBuilder sb = new StringBuilder();
sb.Append("Finished running job ").Append(newJob.CorrelationId);
_loggingService.LogInfo(this, sb.ToString());
}
private void LogNewJobs(IEnumerable<HttpJob> newJobs)
{
StringBuilder sb = new StringBuilder();
sb.Append("Found the following new jobs: ");
foreach (HttpJob httpJob in newJobs)
{
sb.Append(httpJob.CorrelationId).Append(", ");
}
_loggingService.LogInfo(this, sb.ToString());
}
private void LogException(Exception exception)
{
StringBuilder sb = new StringBuilder();
sb.Append("Exception caught in HttpJobRunner:")
.Append(NL).Append("Exception message: ").Append(exception.Message)
.Append(NL).Append("Exception stacktrace: ").Append(exception.StackTrace);
_loggingService.LogError(this, sb.ToString(), exception);
}
As outlined in the expected work flow the HttpJobRunner will first extract the list of new jobs. If there are any new jobs then they are logged. Then each new job is started on its own thread. Within RunSingleHttpJob we first log the start of the job, instruct the execution service to execute the job and finally log the end of the process.
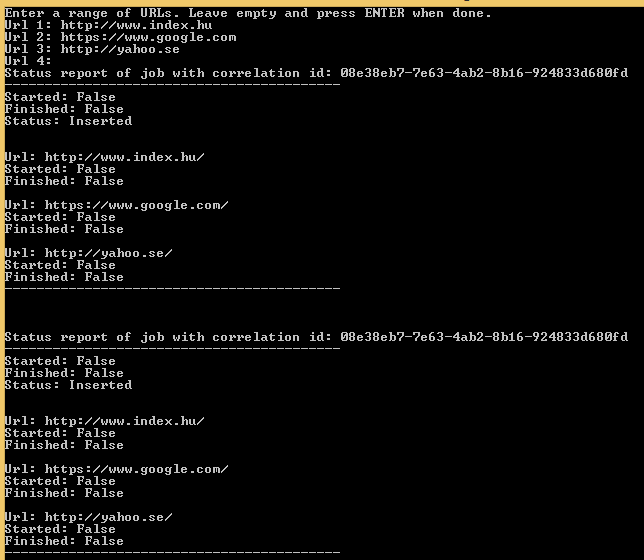
This should be all we need to have a simple but functioning system. Rebuild the solution, uninstall the service and install it again as we did before. Check the log file to make sure the service has “checked in”. Then run the Console app, enter a couple of URLs and wait for the status messages. In my case I got the following:

The same message appeared a couple of times, but then…


…and finally…:
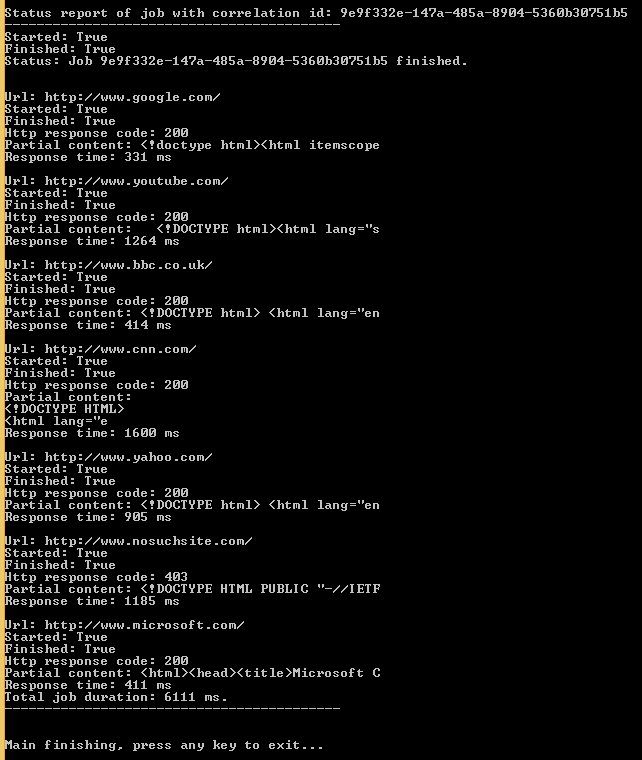
So the job was successfully executed by the HttpJobRunner service. Let’s check the log:
22/09/2014 20:14:58: source: Demo.WindowsService.HttpJobRunner, level: INFO, message: Found the following new jobs: 9e9f332e-147a-485a-8904-5360b30751b5, , any exception: None
22/09/2014 20:14:58: source: Demo.WindowsService.HttpJobRunner, level: INFO, message: About to start job 9e9f332e-147a-485a-8904-5360b30751b5, any exception: None
22/09/2014 20:15:04: source: Demo.WindowsService.HttpJobRunner, level: INFO, message: Finished running job 9e9f332e-147a-485a-8904-5360b30751b5, any exception: None
…which looks fine too.
We’re done, this concludes the series on a possible use of a Windows service in a .NET project. Windows services can be used for other things such as hosting another service, such as WCF, but I wanted to concentrate on their function to execute periodic and/or long running processes.
View the list of posts on Architecture and Patterns here.