In this blog post we’ll put into practice some of the things we’ve gone through in this series on web farms. In particular we’ll take a closer look into the following scenarios:
- How to deploy a web site to a WFF web farm with ARR as the load balancer
- How to set up the state service common to all web farm machines
- How to set up the database state management common to all web farm machines
Deployment
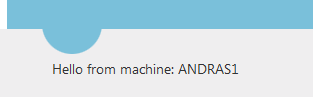
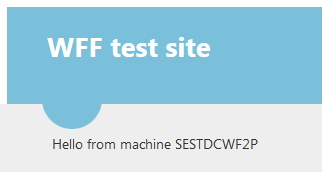
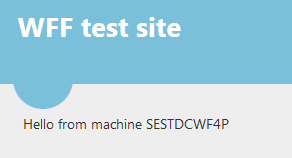
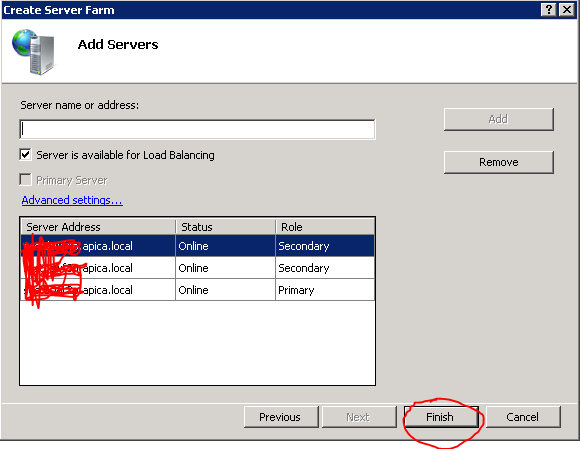
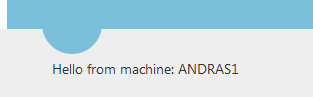
The first thing we want to test is how to deploy our website to the web farm. I’ve prepared a very simple ASP.NET web forms project where the Index page prints out the machine name. I wanted to show some more-or-less unique ID on the screen which shows that we’re getting the response from different machines as the load balancer distributes the web requests. I wanted to make this ID independent of the web site settings as all such settings should be identical throughout the farm. Recall that the primary server is the “leader”, so whatever is deployed on that machine will also be replicated on the secondary servers.
I show the machine name in a label control as follows:
protected void Page_Load(object sender, EventArgs e)
{
if (!IsPostBack)
{
lblUniqueId.Text = GetUniqueIdentifier();
}
}
private string GetUniqueIdentifier()
{
return System.Environment.MachineName;
}
The ID is shown on the index page:
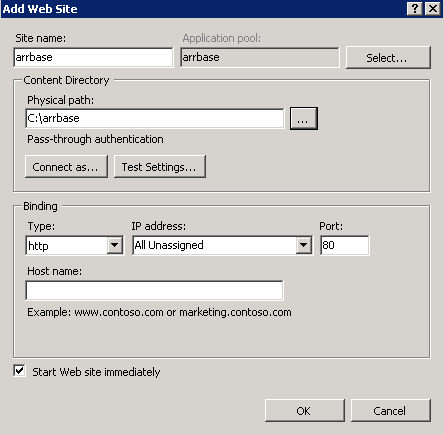
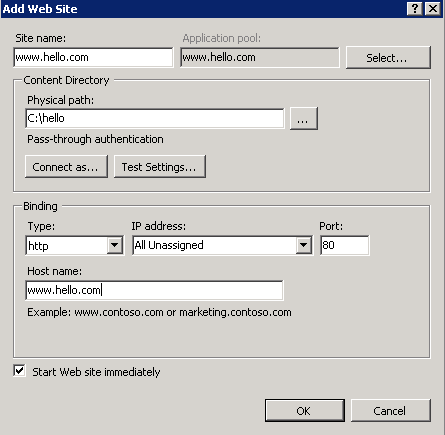
Next I’ll need to create the correct bindings in IIS. Follow these steps:
- Log onto the primary server of the web farm
- Open the IIS manager
- Delete the existing Default Web Site in the Sites folder
- Create a new website: give it some name – I called mine wfftest.apica.local. Leave the host name blank to keep it simple
- Create a folder for the deployment package in the Physical path text box
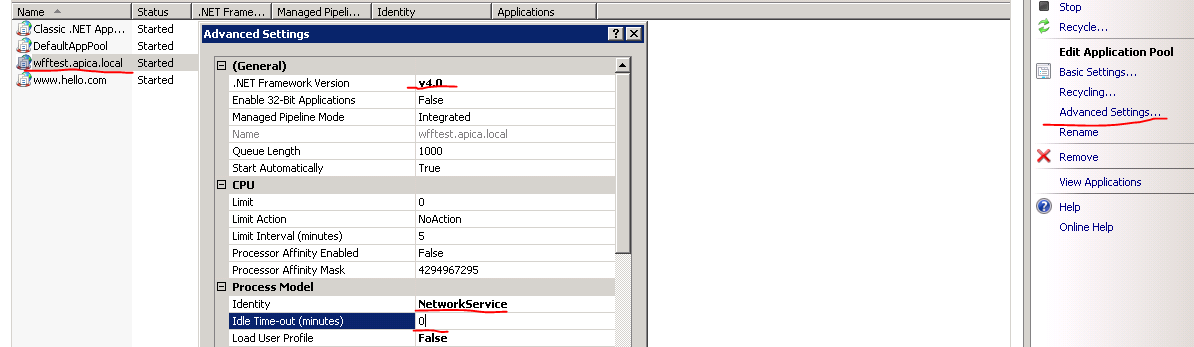
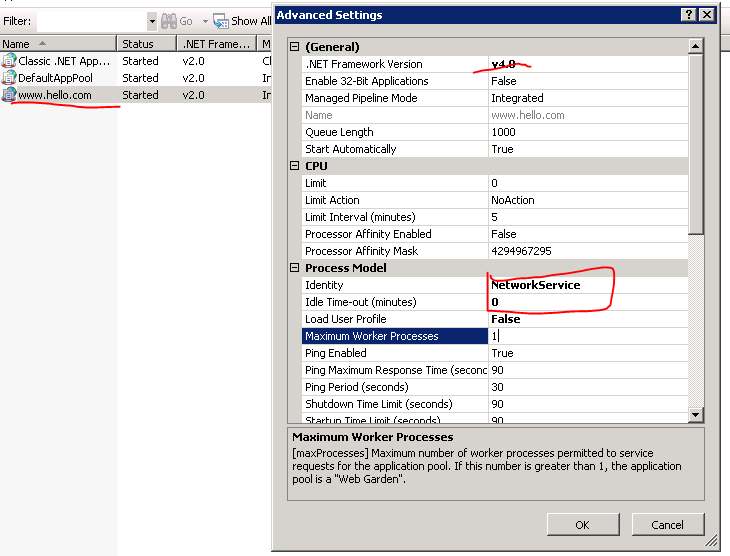
Change the application pool settings as follows:

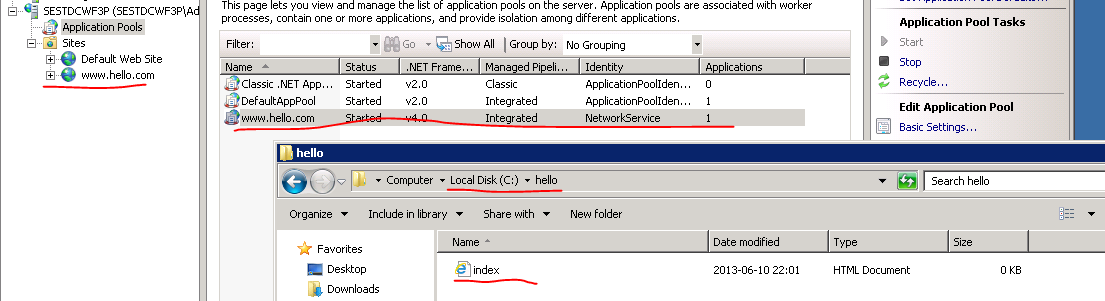
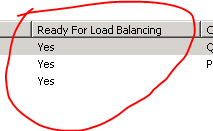
Normally you would have to go through this procedure on every machine of the web farm. However, we have WFF in place, so I’ll log on to one of the secondary servers to see if the changes have been propagated:

I’ll now deploy the web page to the web site folder using the Web Deploy technique we saw in this post. I don’t know about you but I got an exception at first:

Web deployment task failed: make sure web deploy is installed and the required process – Web Management Service – is started.
I’ll show here all the steps I had to take to make this work:
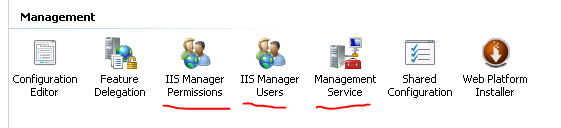
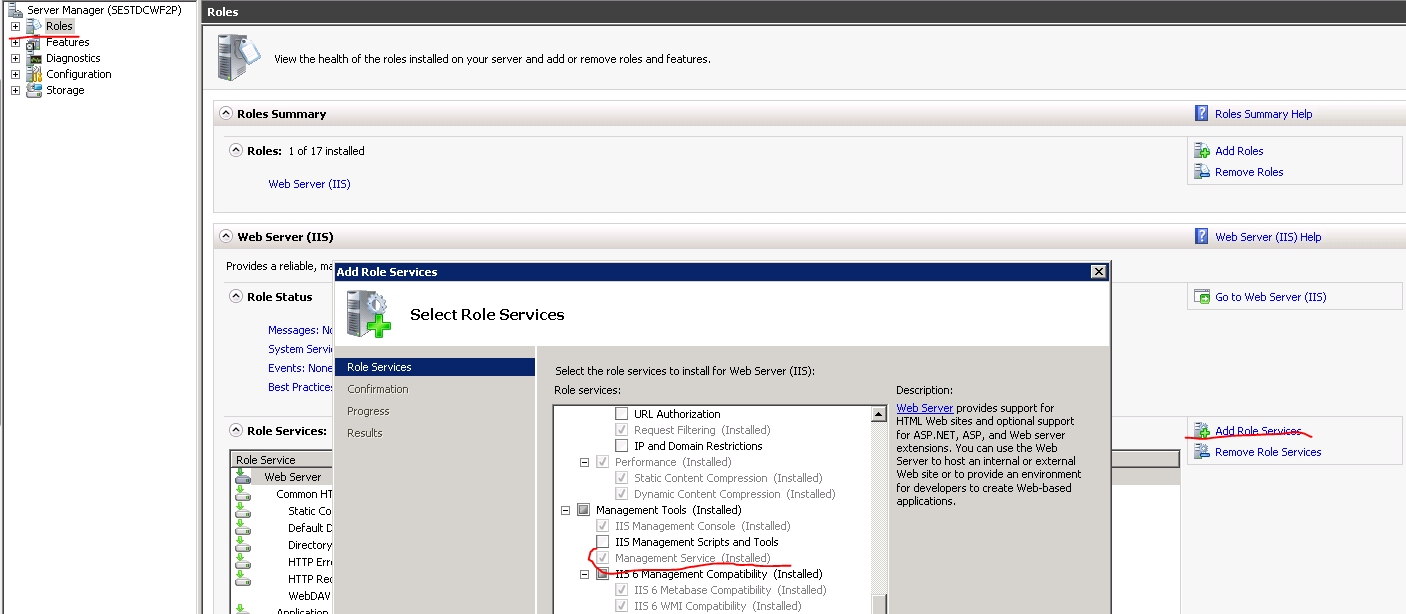
1.) Select the Machine in IIS on the primary server and see if the below icons are available:
If not then you’ll need to enable them. Go to Start, Administrative Tools, Server Manager. Select Roles, Add Role Services and click the Management Service feature:

Click Next and Install. After this refresh the IIS manager window and you should see the three icons that were missing.
2.) Start the service:
Double click the Management Service icon in IIS. Make sure you that remote connections are enabled and you allow for a mixture of credentials. Leave the port number at 8172. Click Start after these changes:

3.) Check your firewall settings:
The following inbound rule must be enabled in the Windows Firewall manager (Start, Administrative tools, Windows Firewall and Advanced Security):

4.) Install Web deploy:
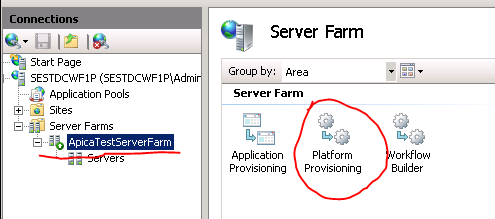
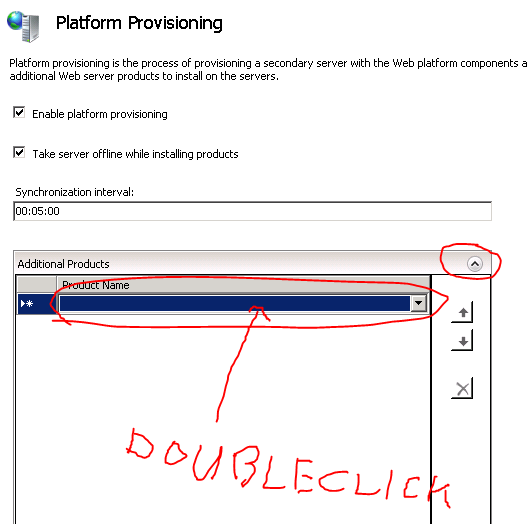
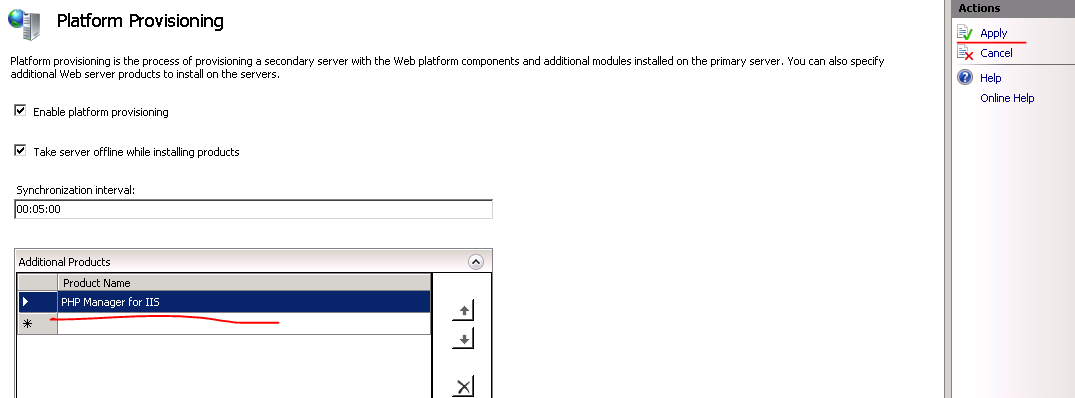
This is easy with WFF. Log onto the controller machine, select Platform provisioning and select Web Deployment Tool 2.1:

Check that the tool is deployed on the primary server:
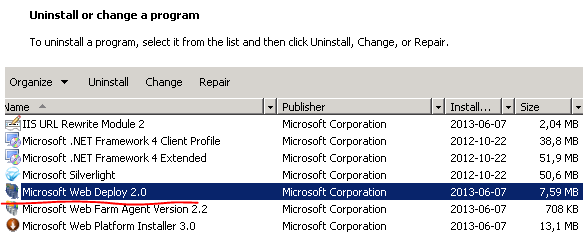
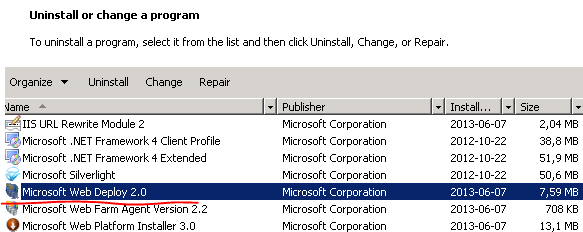
5.) Check if web deployment handler is installed:
In the Programs and Features window shown above right click Microsoft Web Deploy and select Change. Make sure that all features are enabled. You’ll see a red X if they are disabled. Select the following option:

6.) Restart the web management service:

In case none of the above options help then check out the management service log file.
The relevant log file is available on the primary web farm machine under c:/inetpub/logs/WMSvc. There may be an additional folder there, such as W3SVC1. Within that folder you will find a text file, open that. You’ll see some cryptic messages such as:
2013-06-27 13:51:58 192.168.50.102 HEAD /msdeploy.axd site=wfftest.apica.local 8172 – 192.168.100.22 – 404 7 0 234
This means that msdeploy.axd was missing which in turn means that WebDeploy wasn’t installed. Check the numeric codes at the end – I know that due to the IIS response: 404.7. You can find all IIS response codes and subcodes here.
Another problem you may encounter is that IIS doesn’t allow some file extensions. Check the applicationHost.config file on the primary server under c:/windows/system32/inetsrv/config/applicationHost.config. Look for the element called fileExtensions. It has an attribute called allowUnlisted. Set it to true if it’s set to false.
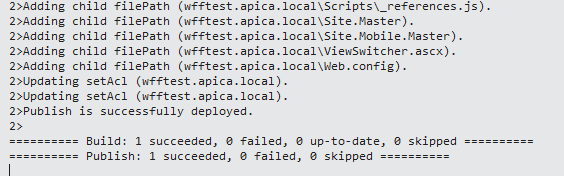
So, after all this I’ve been able to deploy according to VS:
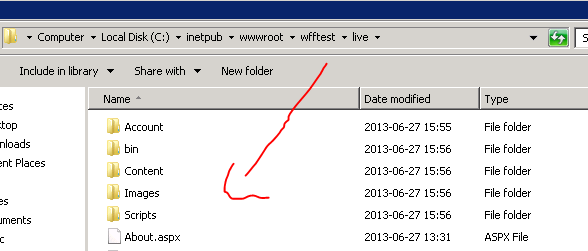
Check that the package has been deployed to the correct folder. In my case it has indeed:
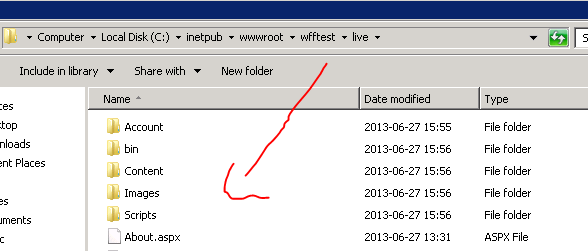
Check the secondary servers as well to see if the controller machine has updated them. You should see that everything is jolly well. We’re making progress! Let’s continue with the setup.
Log onto the controller machine and open the IIS manager. Delete the Default Web Site. Create a new site called arrbase pointing to a blank folder located anywhere you like on c:\. Leave the IP and port values untouched and the Host name field blank:
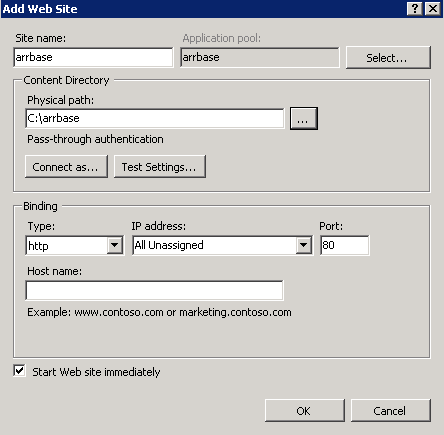
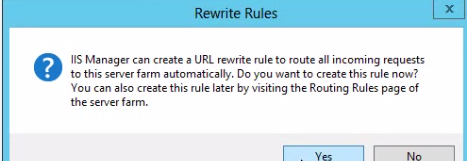
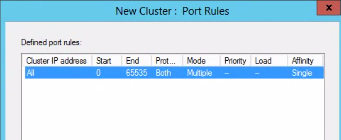
The next step is to set up URL rewrite using ARR. Select the name of the server farm and click the Routing Rules icon:

In case you don’t see it you’ll need to install ARR – I had to install it as well. I assumed that installing WFF would be enough to use the capabilities of ARR but I was wrong. On the controller machine start Web Platform Installer and search for ARR:

Reopen the IIS manager and now you should be able to open Routing Rules. You’ll see that the Use URL Rewrite to inspect incoming requests checkbox is unchecked. Check it and apply the changes:

Now we should be good to go. I re-named my web farm to wfftest.apica.local which is only available from within the company’s intranet where I work:

I asked our technicians to link this URL to the controller machine’s IP so that I can reach it from my machine. An alternative solution is to modify your hosts file at c:\windows\system32\drivers\etc\hosts. Open that file with Notepad using admin rights. Enter the IP of the controller machine and the web farm address, e.g.
192.168.53.412 wfftest.apica.local. Make sure to put a tab in between the IP and the address.
So I enter this address in a web browser on my machine and… :
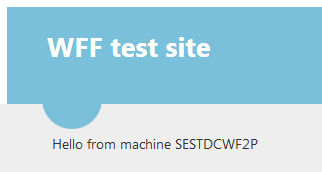
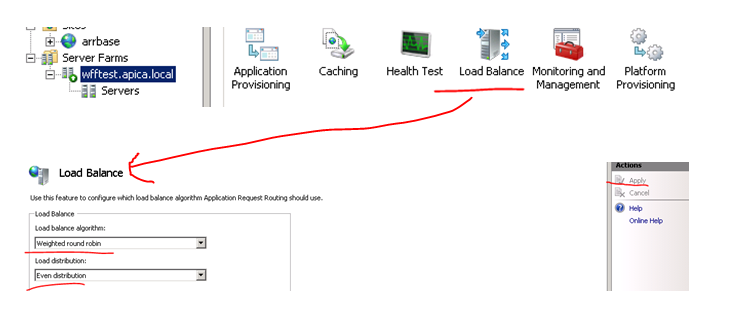
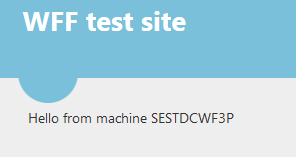
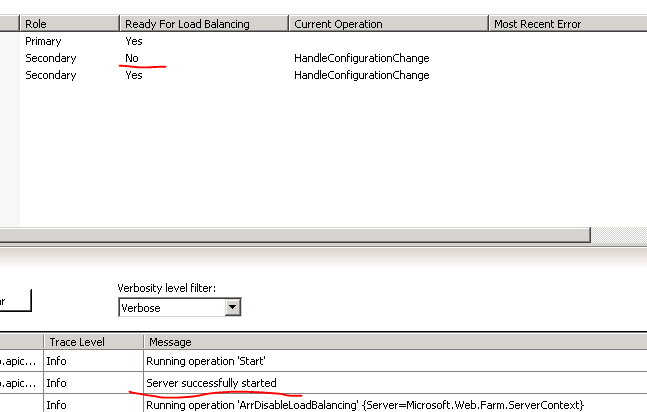
So I got a response from the primary machine in the web farm. I want to check if all 3 machines in the web farm work so I set the load balancing algorithm to round robin:

…and then press F5 a couple of times. Apparently it takes a couple of seconds for the algorithm to be implemented but I get the response from the two secondary servers as well eventually:

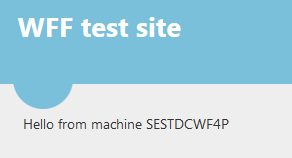
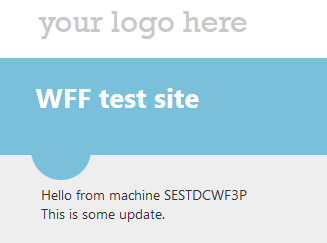
Before we move on let’s re-test the deployment process and we’ll keep an eye on the controller machine. In the web project I add a new line under the “Hello from machine” bit just to be able to check that the changes had been deployed. Watch the controller machine carefully as the deployment process is rather quick:

I then refresh the web page and the updates had indeed been deployed:
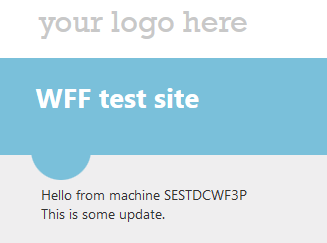
Session management
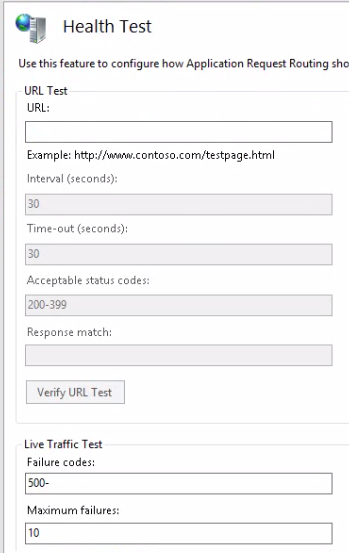
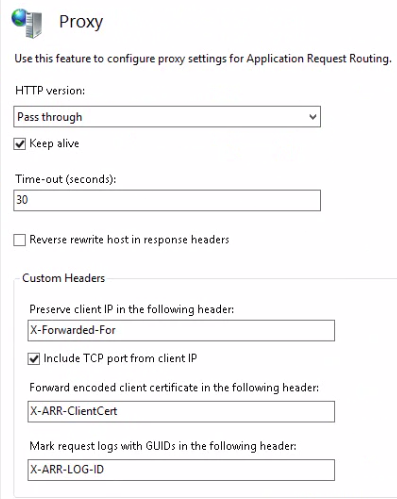
If you have a completely stateless web application, such as a REST web service, then you may as well stop here. You can add some health checks using the techniques shown here to ARR and then you are good to go. You have a functioning web farm with pretty decent provisioning and load balancing features for a relatively low price. If you use caching in your web service then you’ll need to look into some distributed cache solution. A bit more on that in the conclusion part of this post.
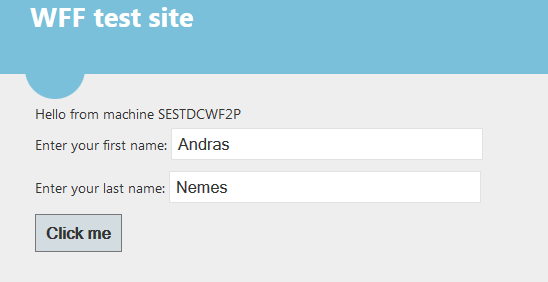
However, web sites are usually stateful. Lots of different data can be stored in session variables to carry them from one page to another. You can read about session management in a web farm in this post, here I only want to test two features outlined there: saving the session in an external state service and alternatively in a database. So make sure you read through that post as I will not repeat the details here. I need to make the model web site use the session state. So I create the following markup in Default.aspx within the MainContent placeholder:
Hello from machine <asp:Label Id="lblMachineName" runat="server" />
<div>
<div>Enter your first name: <asp:TextBox runat="server" ID="txtFirstName"></asp:TextBox></div>
<div>Enter your last name: <asp:TextBox runat="server" ID="txtLastName"></asp:TextBox></div>
<asp:Button Text="Click me" ID="btnSubmit" OnClick="btnSubmit_Click" runat="server" />
</div>
The Submit button has the following click event:
protected void btnSubmit_Click(object sender, EventArgs e)
{
Session["Firstname"] = txtFirstName.Text;
Session["Lastname"] = txtLastName.Text;
Response.Redirect("~/About.aspx");
}
I modified the HTML on About.aspx as follows:
<article>
Hello from machine <asp:Label Id="lblMachineName" runat="server" />
<p>
<asp:Label Text="" ID="lblFirstName" runat="server" /><br />
<asp:Label Text="" ID="lblLastName" runat="server" />
</p>
</article>
…with the Page_Load event of About.aspx.cs looking like this:
protected void Page_Load(object sender, EventArgs e)
{
if (!IsPostBack)
{
lblFirstName.Text = Session["Firstname"] != null ? string.Concat("Your first name is: ", Convert.ToString(Session["Firstname"])) : "There's no First name in the session!";
lblLastName.Text = Session["Lastname"] != null ? string.Concat("Your last name is: ", Convert.ToString(Session["Lastname"])) : "There's no Last name in the session!";
lblMachineName.Text = System.Environment.MachineName;
}
}
I believe this is easy to follows. Let’s now deploy the project as it is without making changes to session handling and see what happens. So I fill in my first and last name and press the Click me button and… …I got an exception saying that validation of viewstate MAC has failed:

So we are required to change the session state management anyway. I took the following steps to set up a state service:
- Picked a development machine separate from the web farm machines but still within the same intranet
- Started the Windows service called ASP.NET State Service on that machine
- Changed the registry key HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\aspnet_state\Parameters\AllowRemoteConnection value to 1 on that machine and restarted the state service
- Declared in web.config that session state must be handled through a state server using the address of the state server, which is the dev machine in my case I mentioned under point 1
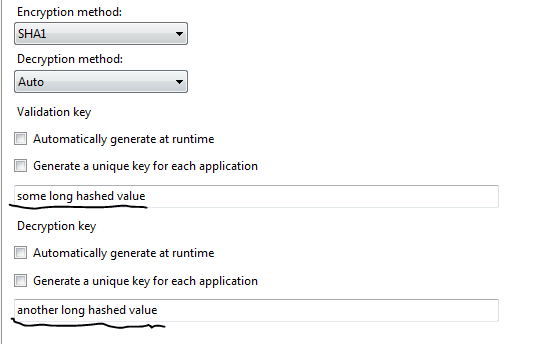
- I inserted a machine key in web.config which will be common to all machines in the web farm
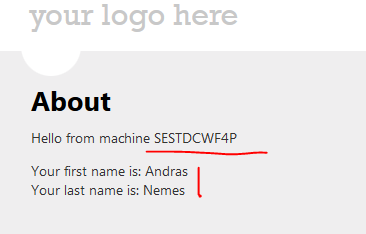
So I redeploy the web app and land on the primary machine. I enter my first and last name and press the button:
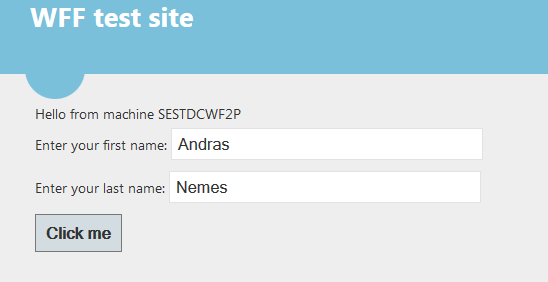
…and…
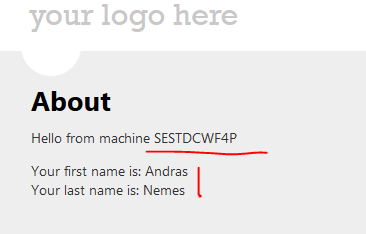
That’s looking really good. We ended up on a different machine and the state is still available. Refresh the About page to land on different machines and you’ll see that the state is available.
OK, let’s try to save the session in a database now. I performed the following steps:
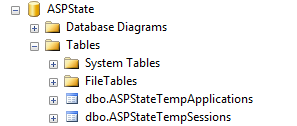
- Set up the ASPState table in a database available to all machines in the web farm using the aspnet_regsql.exe tool: aspnet_regsql.exe -ssadd -sstype p -S [database machine name] -U [db admin username] -P [db admin password]
- Check the database and I see the following table structure:
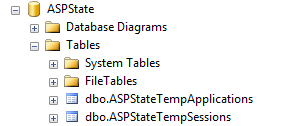
- Update the sessionState tag in web.config (details below)
My sessionState element in web.config looks as follows:
<sessionState mode="SQLServer" allowCustomSqlDatabase="true" sqlConnectionString="ASPStateConnectionString">
</sessionState>
…where ASPStateConnectionString refers to a connection string in web.config which has the following format:
<add name="ASPStateConnectionString" connectionString="Data Source=[DB machine name];Initial Catalog=ASPState;User ID=xxx;Password=xxxxx"
providerName="System.Data.SqlClient" />
I deploy the web app as usual and perform the same test as above. It went well so I check the entries in the ASPState database:

So we have successfully tested the most basic session management features for an IIS web farm.
A short addition: you can add an extra level of security to the database type of solution by synchronising your primary SQL server with a secondary one which serves as a failover solution. You can achieve this using the technology called SQL AlwaysOn. That way if your primary server fails then the sessions will be available from your failover server. If you find that the database solution is too slow but don’t want to take the risk of your state server going down then you can check out Memcached which is a free tool that offers a highly available short-term caching solution. An alternative solution is CouchBase.
Conclusion and possible improvements
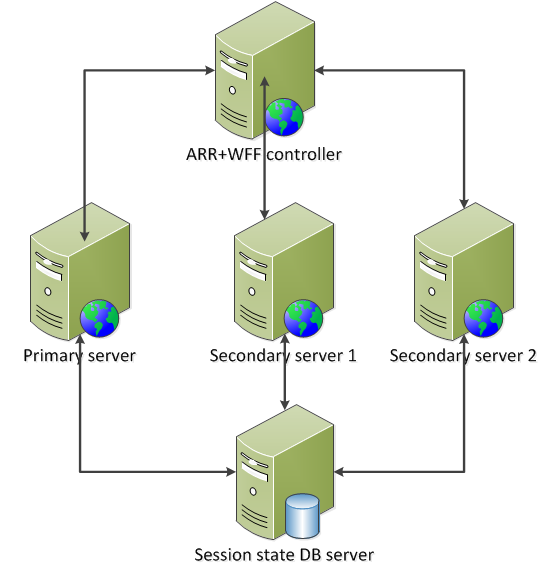
We currently have the following model:
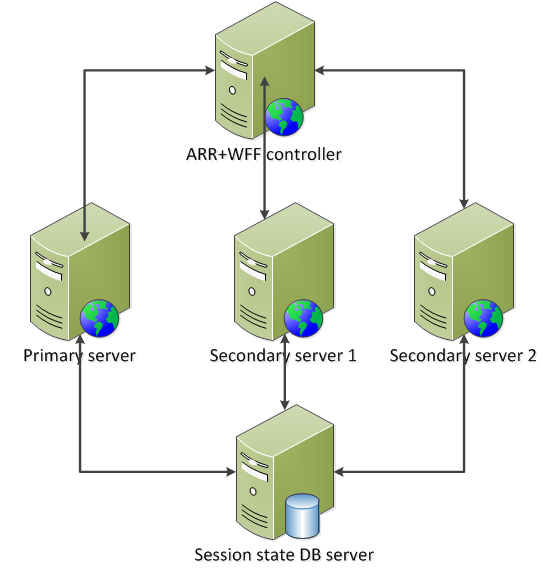
This is a good foundation but we still have a couple of vulnerability points:
- ARR doesn’t provide high availability and scalability in itself – the solution is to set up an identical load balancing machine with ARR and NLB and install NLB on the existing ARR machine as well. Here‘s a good guide on how to proceed. The key idea is to provide a virtual IP for the two ARR+NLB machines where NLB is responsible for high availability
- ARR and WFF are located on the same machine, but there’s nothing stopping you from putting them on two different machines: if this machine dies then WFF can still control the web farm
- Set up another state DB machine and put SQL AlwaysOn in place in order to synchronise it with the main state DB
- The WFF controller can still die and then there’s no content replication from the primary server to the secondary ones: at present this cannot be helped, i.e. there’s no high availability solution for the controller machine in WFF2.2 – your best bet is to monitor this machine externally and react quickly if it goes offline and avoid deploys during this time. However, even if it goes down your web farm will still be responding to web request – provided that the load balancer is located on a different machine
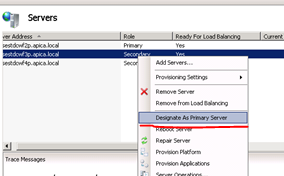
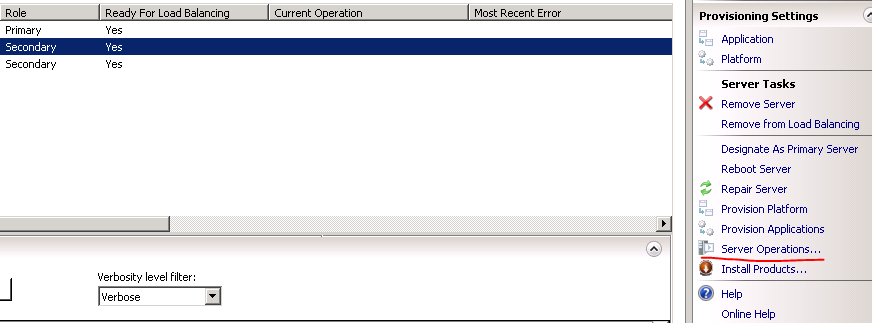
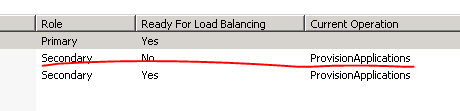
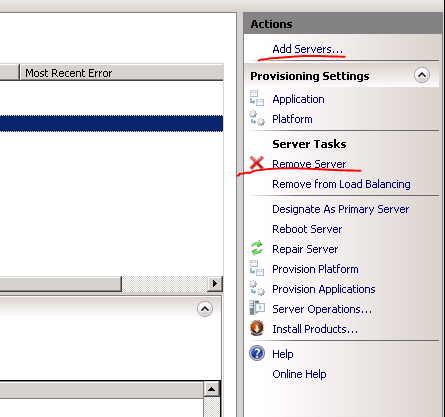
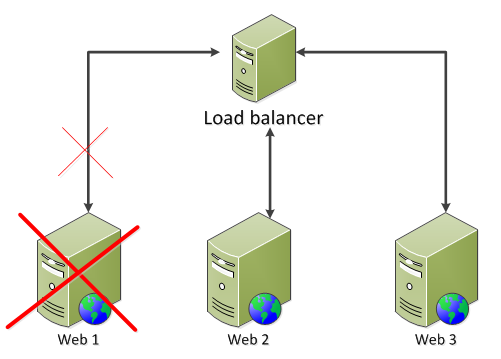
- The primary server can of course also go down meaning you cannot deploy to it and WFF will not be able to replicate its content to the secondary servers – the solution is straightforward: just designate another primary server, check the screenshot below
To designate a secondary server as the primary one in the WFF GUI:
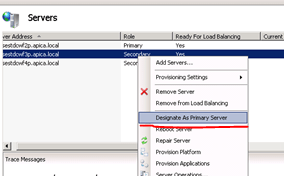
Right-click the secondary server name and select “Designate as Primary Server” from the context menu.
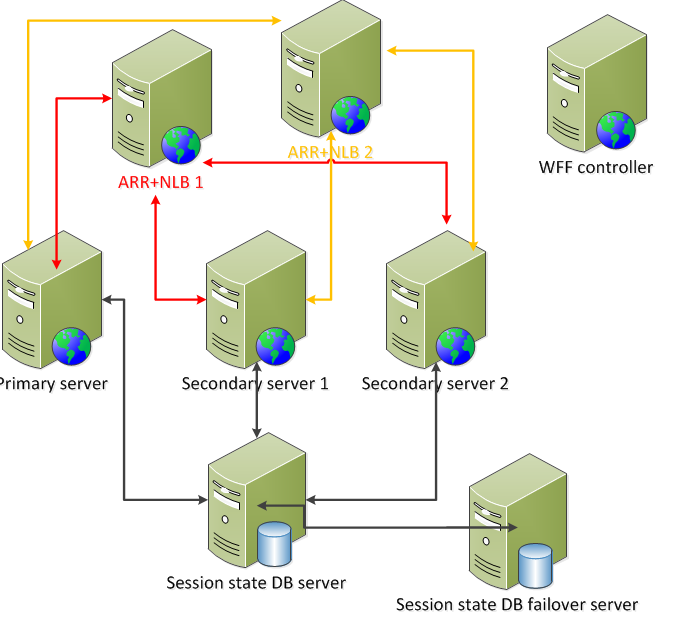
So if we implement the solutions suggested above to solve the weak points of our current architecture we may end up with something like this:

This is a cost-effective high availability and high scalability system using well tested and reliable software solutions. You can add new web servers to your farm and then update the servers list on the ARR+NLB machines and on the WFF controller.
Caching
We haven’t talked much about caching yet. Say that you’d like to cache the results of the database query using one of the several built-in caching mechanisms in .NET: ObjectCache, HttpCache etc. If you cache the result on web farm machine A then that cached value will not be available on machine B automatically. Both machine A and B will have the cached value in their memory eventually if the web requests are routed to both of them, but their expiry date will be different. Maybe machine A will fetch a more recent result of the database query than machine B because machine B stores the value with a later expiry date. So essentially we’ll need a similar distributed solution for caching as for session management: the cached values should be available on separate machines that all web farm members have access to. We mentioned Memcached and CouchBase before in this post. They are both really good products with a .NET library.
CouchBase has an advantage over Memcached: in case you set up more than one external cache machine – a good idea if you need a failover solution here as well – then it’s desirable for the cache machines to synchronise their cache data as soon as there’s a change. We don’t want to the cache machines to return different objects for the same cache key, right? Memcached servers don’t talk to each other so you may actually end up with that scenario. CouchBase servers however provide synchronisation: say that web farm member A writes to the cache; this object with a certain cache key will be sent to the CouchBase server cluster. CouchBase will make sure that all cache machines in the cluster will have this updated value.
You can even use CouchBase to take care of session management for you if you don’t like the database solution outlined above. You replace the sessionState node in web.config to use an external session management solution. After all, session values are key-value pairs, much like cached objects.
Pre-compiled web package
One last improvement that I want to mentioned is pre-compiled websites. In the present solution if you deploy the web package then it must be compiled on the server when the first web request comes in after the deploy. This can cause a slight delay in the response time for the first visitor. It is possible with MSDeploy to pre-compile your web project before deploy. You can even automate that using your Continuous Integration server, such as TeamCity.
If you perform all the suggested improvements then you’ll end up with a distributed system which has the following characteristics:
- High availability
- High scalability
- Distributed, highly available cache service
- Distributed, highly available session state service
- Automated content replication
- Seamless deployment from the client’s point of view: the cache and the state are still available during and after a web deploy and the client doesn’t see a longer response time on the first web request