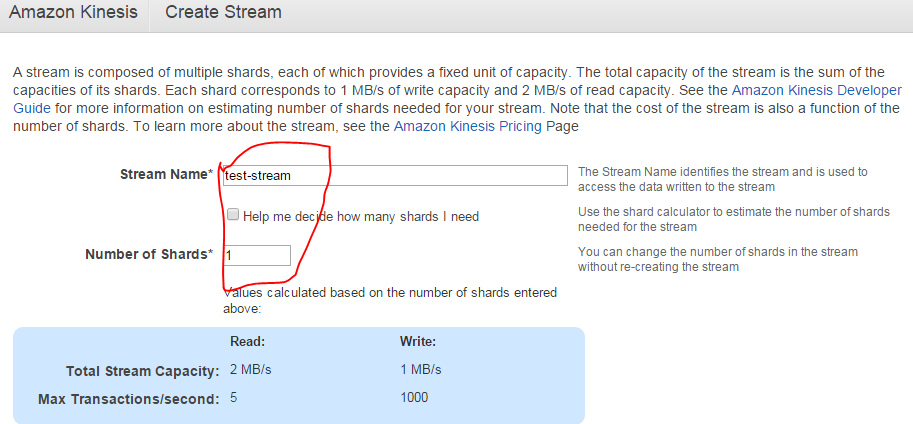
Using Amazon S3 with the AWS.NET API Part 1: introduction
January 1, 2015 2 Comments
Introduction
Cloud-based blob storage solutions are abound and Amazon Web Services (AWS) is the leader – or one of the leaders – in that area. Amazon S3 (Simple Storage Service) provides a “secure, durable, highly-scalable object storage” solution, as it is stated on the homepage. You can use S3 to store just about any type of file: images, text files, videos, JAR files, HTML pages etc. All files are stored in a key-value map, i.e. each file has a key where the file itself is the value.
Purpose of S3
S3 is often used to store static components of web pages such as images or videos. S3 can be integrated with other Amazon components such as RedShift and Elastic MapReduce. It can also be used to transfer large amounts of data from one component to another.
However, in this series we’ll be concentrating on a slightly different but very specific usage: saving, deleting and checking for the existence of text based storage files. S3 can function as an important building block in a Big Data analysis system where a data mining application can pull the raw data from an S3 bucket, i.e. a container of files.
In S3 you can organise your files into pseudo-folders. I wrote “pseudo” as they are not real folders like the ones we create on Windows. The are rather used as visual containers so that you can organise your files in a meaningful way instead of putting all of them under the same bucket. Examples:
s3:\\sales\january-2015\monthly-sales.txt
s3:\\sales\february-2015\monthly-sales.txt
“sales” is the top bucket, “january-2015” is folder and then we have the file itself. You are free to create subfolders within each folder and subfolders within the subfolders etc.
Keep in mind that S3 is not used for updates though. Once you’ve uploaded a file to S3 then it cannot be updated in a one-step operation. Even if you want to edit a text file there’s no editor for it. You’ll need to delete the old file and upload a new one instead.
Amazon have also done a great job at providing SDKs for a range of platforms, like .NET, Java, Python etc. Programmatic access to S3’s services is equally available.
As with many other Amazon components don’t assume that S3 can only be used with other Amazon components. Any software capable of executing HTTP calls can use to access S3: Web API, .NET MVC, iOS, Java desktop apps, Windows services, you name it. Mixed architecture is quickly becoming the norm nowadays and S3 can be used both as part of a mixed solution or as an Amazon-only architecture.
Goals of this series
The goals of this series are two-fold:
- Provide basic UI and programmatic knowledge to anyone looking for a fast, cheap, reliable and scalable cloud-based blob storage solution
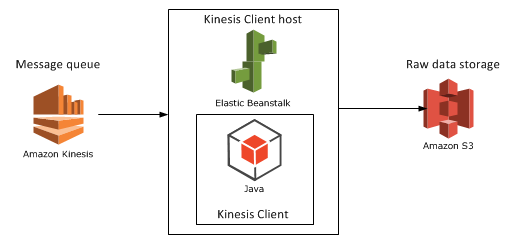
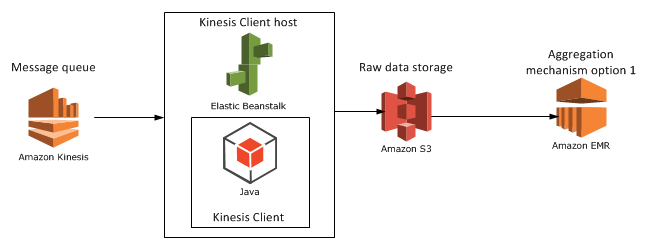
- Tie in with the previous series about another Amazon service called Kinesis which provides a reliable message queue service as entry point to a Big Data data mining system. We’ll take up S3 as an alternative for raw data storage towards the end of the series. The series on Kinesis ended where we stored the raw data on a local text file – we’ll replace it with S3 based storage
I’ll try to keep the two goals as separate as possible so that all readers with different motivations can follow through – those of you who are only interested in S3 as well as those that will see the greater picture.
I’ll assume that you have at least a test account of Amazon Web Services including the necessary access keys: an Amazon Access Key and a Secret Access Key. You’ll need to sign up with Amazon and then sign up for S3 within Amazon. You can create a free account on the S3 home page using the Create Free Account link button:
Amazon has a lot of great documentation online. Should you get stuck you’ll almost always find an answer there. Don’t be afraid to ask in the comments section below.
In this post we’ll take an easy start and go through some of the visual aspects of S3.
S3 GUI
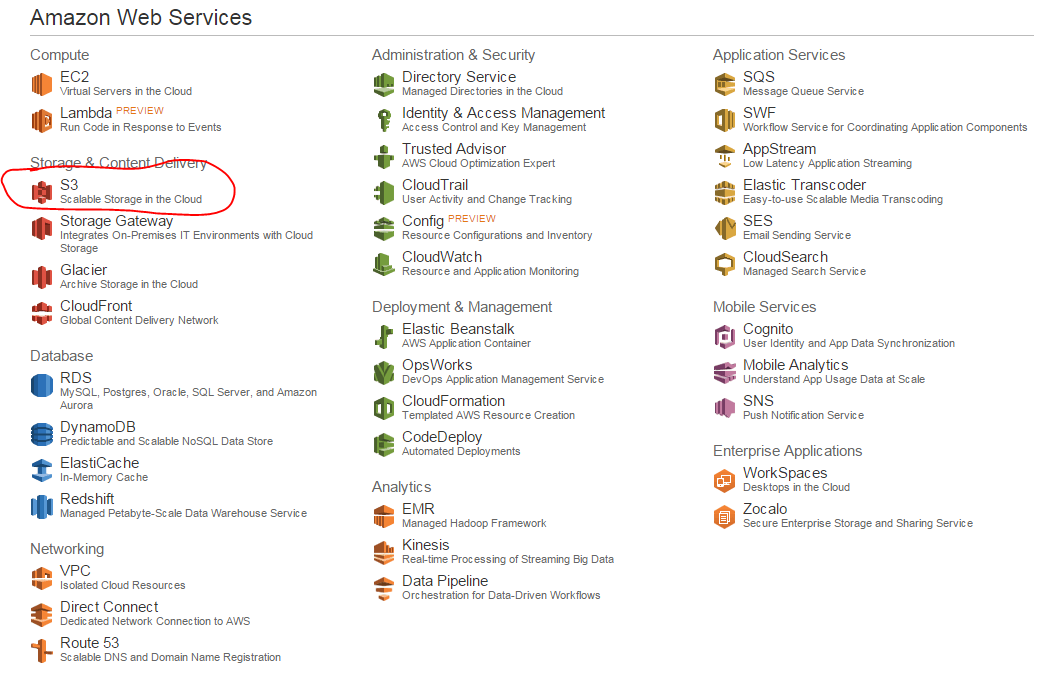
Log onto AWS and locate the S3 service link:
Before we go anywhere it’s important to mention regions in Amazon. A region in Amazon Web Services is the geographical location of the data centre where your selected service will be located. E.g. if you create a cloud-based server with Amazon EC2 in the region called US East then the server will be set up North Virginia. It doesn’t mean that your home page deployed on that server won’t be reachable anywhere else, it only means the physical location of the service. So if you’re expecting the bulk of your customers to come from Japan then it’s wise to set up the first web server in the region called Asia Pacific (Tokyo). Also, if you set up a service in e.g. EU (Ireland) on the AWS UI, then log out and log in again, your service may not be visible at first. A good guess is that you need to select the correct region. The region is indicated in the URL, e.g.:
https://console.aws.amazon.com/s3/home?region=eu-west-1#
…where “eu-west-1” stands for EU (Ireland). You can normally select the region in the top right hand corner of the Amazon UI where you’ll see the user-friendly names of the regions.
Regions are important for virtually all the components in AWS. Take a wild guess, which component is an exception. Check out the top right hand corner of the S3 screen:

So regions don’t play the same role here as in other components in the AWS product offering. However, the selected region can still be used to “optimize for latency, minimize costs, or address regulatory requirements” as it says in the Create a Bucket windows we’ll soon see.
You’ll see that by default the screen will show all the top buckets:

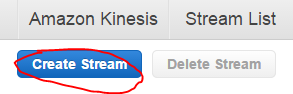
Let’s try a couple of things to get our hands dirty. Click on the Create Bucket button. Give the bucket a name, select the nearest region to your location and press Create. We’ll skip logging right now:

The bucket is quickly created:

On the right hand side of the screen you can set various properties of the bucket such as logging and security:
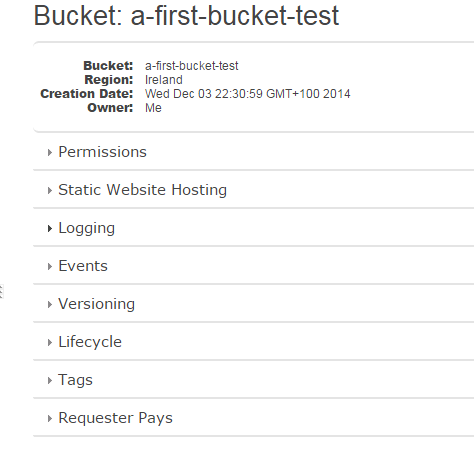
We won’t go into them at all otherwise this series will lose its scope. The default values are usually fine for most purposes. If you ever need to modify the settings, especially those that have to do with permissions, then consult the AWS documentation of S3.
Click on the name of the bucket and you’ll see that it’s empty:

Click the Upload button and click Add Files:

Select some file on your hard drive, preferably a text file as they are easier to open. Click “Start Upload” and the file upload progress should appear on the right hand side:
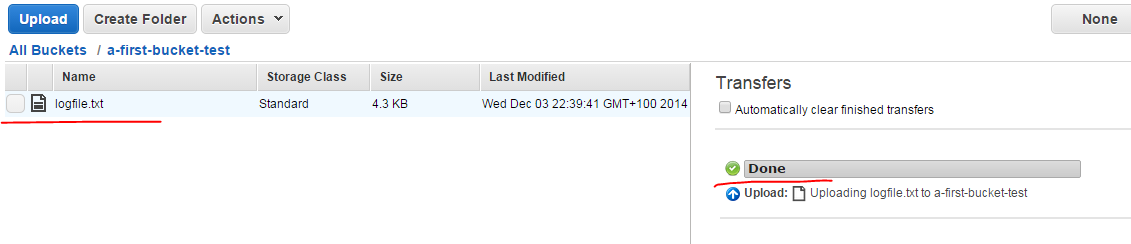
Click the file name to select it. The Actions drop-down will list several options available for a file such as Open, Download or Delete which are self-explanatory.
Now click the “Create Folder” button and give the folder a name:
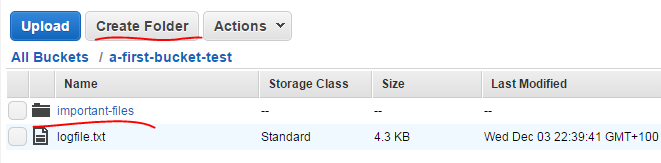
You can click the folder name to open its contents – much like you do it with a double-click on the Windows file system. You can then upload different files in that folder and create subfolders.
This is enough for starters. We’ll start looking into some basic operations in code in the next post.
View all posts related to Amazon Web Services and Big Data here.