Architecture of a Big Data messaging and aggregation system using Amazon Web Services part 3
December 13, 2014 Leave a comment
Introduction
In the previous post of this series we went through a possible data storage solution for our raw data points. We said that Amazon S3 was a likely candidate for our needs. We also discussed a little bit how the raw data points should be formatted in the storage files and how the S3 buckets should be organised.
In this post we’ll see how to deploy our Java Kinesis Client app and we’ll also look into a possible mechanism for data aggregation.
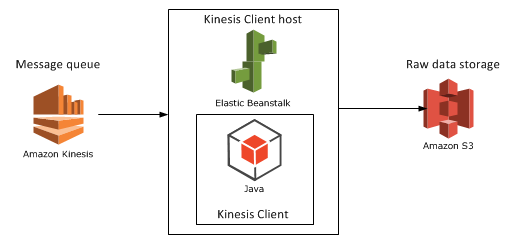
Deploying the Kinesis client application: Beanstalk for Java
We’ll need to see how the Kinesis client application can be deployed. It doesn’t make any difference which technology you use: Java, .NET, Python etc., the client app will be a worker process that must be deployed within a host.
Currently I’m only familiar with hosting Java-based Kinesis client applications but the proposed solution might work for other platforms. Amazon’s Elastic Beanstalk offers a highly scalable deployment platform for a variety of application types: .NET, Java, Ruby etc. For a .NET KCL app you may be looking into Microsoft Azure if you’d like to deploy the solution in the cloud.
Beanstalk is a wrapper around a full-blown EC2 machine with lots of details managed for you. If you start a new EC2 instance then you can use your Amazon credentials to log onto it, customise its settings, deploy various software on it etc., in other words use as a “normal” virtual machine. With Beanstalk a lot of settings will be managed for you and you won’t be able to log onto the underlying EC2 instance. Beanstalk also lets you manage deployment packages and you can easily add new environments and applications and deploy different versions of your product on them. It is an ideal platform to house a worker application like our Kinesis client. You can also add autoscaling rules that describe when a new instance should be added to a cluster. So you’ll get a lot of extras in exchange for not having the full control over the EC2 instance.
I’ve written an article on how to deploy a Kinesis client application on Beanstalk available here.
Let’s add Beanstalk as the Kinesis client host to our diagram:
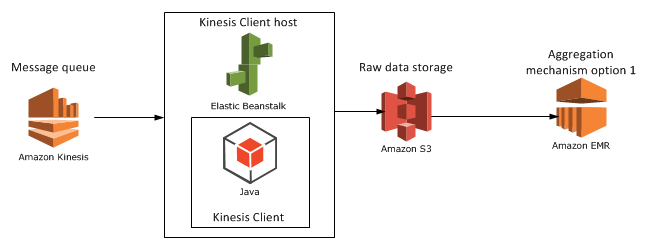
Aggregation mechanism option 1: Elastic MapReduce
Elastic MapReduce (EMR) is Amazon’s web service with the Hadoop framework installed. What’s MapReduce? I’ve introduced MapReduce in an unrelated post elsewhere on this blog. I’ll copy the relevant section for a short introduction:
Short summary of MapReduce
MapReduce – or Map/Filter/Reduce – is eagerly used in data mining and big data applications to find information from a large, potentially unstructured data set. E.g. finding the average age of all Employees who have been employed for more than 5 years is a good candidate for this algorithm.
The individual parts of Map/Filter/Reduce, i.e. the Map, the Filter and the Reduce are steps or operations in a chain to compute something from a collection. Not all 3 steps are required in all data mining cases. Examples:
- Finding the average age of employees who have been working at a company for more than 5 years: you map the age property of each employee to a list of integers but filter out those who have been working for less than 5 years. Then you calculate the average of the elements in the integer list, i.e. reduce the list to a single outcome.
- Finding the ids of every employee: if the IDs are strings then you can map the ID fields into a list of strings, there’s no need for any filtering or reducing.
- Finding the average age of all employees: you map the age of each employee into an integer list and then calculate the average of those integers in the reduce phase, there’s no need for filtering
- Find all employees over 50 years of age: we filter out the employees who are younger than 50, there’s no need for mapping or reducing the employees collection.
MapReduce implementations in reality can become quite complex depending on the query and structure of the source data.
You can read more about MapReduce in general here.
EMR continued
Hadoop is eagerly used in the distributed computing world where large amounts of potentially unstructured input files are stored across several servers. The final goal is of course to process these raw data files in some way, like what we’re trying to do in this series. If you’re planning to work with Big Data and data-mining then you’ll definitely come across Hadoop at some point. Hadoop is a large system with a steep learning curve.
Also, there’s a whole ecosystem built on top of Hadoop to simplify writing MapReduce functions and queries. There are even companies out there, like Hortonworks, who specialise in GUI tools around Hadoop so that you don’t have to write plain queries in a command line tool.
Some of the technologies around Hadoop are the following:
- Java MapReduce: you can write MapReduce applications with Java. These are quite low-level operations and probably not too many Big Data developers go with this option in practice but I might be wrong here
- Hive: an SQL-like language that creates Java MapReduce functions under the hood and runs them. This is a lot less complex solution than writing a Java MapReduce function
- Pig: Pig – or Pig Latin – is another language/technology to handle large amounts of data in a fast, parallel and efficient way
…and a whole lot more but Hive and Pig seem to be the most popular ones at the time of writing this post.
Hadoop is normally installed on Linux machines although it can be deployed on Windows with some tricks – and luck :-). However, on production systems you’ll probably not want to have Hadoop on Windows. Therefore if you start a new instance of EMR in Amazon then you’ll be given a Linux EC2 machine with Hadoop and a couple of other tools installed, e.g. Hive and Pig will follow along although you can opt out of those when you start a new Hadoop instance. It’s good to have them installed so that you can test your Hive/Pig scripts on them.
Connecting EMR with S3
Now the big question is how we can import the S3 data and analyse them on a Hadoop EMR instance. Amazon extended the Hive language so that it can easily interact with S3. The following Hive statement imports all files from a given S3 bucket. Note that every record within the S3 bucket/folder will be imported, you don’t need to provide the file names.
CREATE EXTERNAL TABLE IF NOT EXISTS raw_data_points (customerId string, url string,date string,response_time int,http_verb string,http_response_code int) PARTITIONED BY (customerId string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LOCATION 's3://raw-data-points/00-15-11-10-2014';
I won’t go into every detail of these statements, you’ll need to explore Hive yourself, but here’s the gist of it:
- We create a temporary table with the columns listed in brackets
- We indicate that the fields in the raw data source are delimited by ‘,’
- Finally we show where the raw data files are located
You can then run the Hive aggregation functions on that temporary table and export the result into another data source – which we’ll explore later. You can probably achieve the same with Pig, which is claimed to run faster than Hive, but I’m not familiar with it at all.
We’ll look at another candidate for the aggregation mechanism, RedShift in the next post. For the time being let’s add EMR to our diagram:
View all posts related to Amazon Web Services here.

