Architecture of a Big Data messaging and aggregation system using Amazon Web Services part 4
December 14, 2014 Leave a comment
Introduction
In the previous post we looked at two components in our architecture:
- Elastic Beanstalk to host the Java Kinesis Client Application
- Elastic MapReduce, a Hadoop-based Amazon component as an alternative data aggregation platform
In this post we’ll look at another AWS component that very well suits data aggregation jobs: RedShift.
Amazon RedShift
Amazon RedShift is Amazon’s data warehousing solution. It follows a columnar DBMS architecture and it was designed especially for heavy data mining requests.
RedShift is based on PostgreSQL with some Amazon specific additions e.g. for importing raw data values from and S3 bucket. PostgreSQL syntax is very similar to other SQL languages you may be familiar with such as MS SQL. Therefore learning the basics of the language doesn’t require a lot of time and effort and you can become productive quite fast.
Having said all that, here comes a warning – a serious warning. The version of PostgreSQL employed on RedShift has some serious limitations compared to the full blown PostgreSQL. E.g. stored procedures, triggers, functions, auto-incrementing primary keys, enforced secondary keys etc. are NOT SUPPORTED. RedShift is still optimised for aggregation functions but it’s a good idea to be aware of the limits. This page has links to the lists of all missing or limited features.
RedShift vs. Elastic MapReduce
You may be asking which of the two aggregation mechanism is faster, EMR with Hive or RedShift with PostgreSQL. According to the tests we’ve performed in our project RedShift aggregation jobs run faster. A lot faster. RedShift can also be used as the storage device for the aggregated data. Other platforms like web services or desktop apps can easily pull the data from a RedShift table. You can also store the aggregated data on EMR on the Hadoop file system but those are not as readily available to other external platforms. We’ll look at some more storage options in the next part of this series so I won’t give any more details here.
This doesn’t mean that EMR is completely out of game but if you’re facing a scenario such as the one described in this series then you’re probably better off using RedShift for the aggregation purposes.
DB schema for RedShift
Data warehousing requires a different mindset to what you might be accustomed to from your DB-driven development experience. In a “normal” database of a web app you’ll probably have tables according to your domain like “Customer”, “Product”, “Order” etc. Then you’ll have secondary keys and intermediate tables to represent 1-to-M and M-to-M relationships. Also, you’ll probably keep your tables normalised.
That’s often simply not good enough for analytic and data mining applications. In data analysis apps your customers will be after some complex aggregation queries:
- What was the maximum response time of /Products.aspx on my web page for users in Seattle using IE 10 on January 12 2015?
- What was the average sales of product ‘ABC’ in our physical shops in the North-America region between 01 and 20 December 2014?
- What is the total value of product XYZ sold on our web shop from iOS mobile apps in France in February 2015 after running a campaign?
You can replace “average” and “maximum” with any other aggregation type such as the 95th-percentile and median. With so many aggregation combinations your aggregation scripts would need to go through a very long list of aggregations. Also, trying to save every thinkable aggregation combination in different tables would cause the number of tables to explode. Such a setup will require a lot of lookups and joins which greatly reduce the performance. We haven’t even mentioned the difficulty with adding new aggregation types and storing historical data.
Data mining applications have adopted two schema types specially designed to solve this problem:
- Star schema: a design with a Fact table in the middle and one or more Dimension tables around. The dimension tables are often denormalised
- Snowflake schema: very similar to a star schema but the dimension tables are normalised. Therefore the fact table is surrounded by the dimension tables and their own broken-out sub-tables
I will not even attempt to describe these schema types here as the post – and the series – would explode with stuff that’s out of scope. I just wanted to make you aware of these ideas. Here’s an example for each type from Wikipedia to give you a taste.
Star:
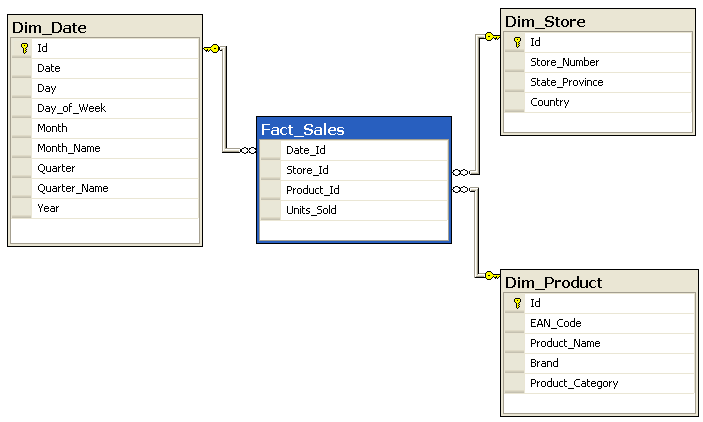
Snowflake:

They are often used by analytic applications such as SQL Server Analysis Services. If you’re planning to take on data mining at a serious level then it’s inevitable to get accustomed with them.
Of course, if you’re only planning to support some basic aggregation types then such schema designs may be overkill. It all depends on your goals.
RedShift is very well suited for both Star and Snowflake schema types. There’s long article that goes through Star and Snowflake in RedShift available here.
Let’s add RedShift to our diagram as another alternative:

In the next post – which will finish up this series – we’ll look into potential storage mechanisms for both RedShift and EMR.
View all posts related to Amazon Web Services here.

