Architecture of a Big Data messaging and aggregation system using Amazon Web Services part 1
December 6, 2014 1 Comment
Introduction
Amazon has a very wide range of cloud-based services. At the time of writing this post Amazon offered the following services:

It feels like Amazon is building a solution to any software architecture problem one can think of. I have been exposed to a limited number of them professionally and most of them will figure in this series: S3, DynamoDb, Data Pipeline, Elastic Beanstalk, Elastic MapReduce and RedShift. Note that we’ll not see any detailed code examples as that could fill an entire book. Here we only talk about an overall architecture where we build up the data flow step by step. I’m planning to post about how to use these components programmatically using .NET and Java during 2015 anyway.
Here’s a short description of the system we’d like to build:
- A large amount of incoming messages needs to be analysed – by “large amount” we mean thousands per second
- Each message contains a data point with some observation important to your business: sales data, response times, price changes, etc.
- Every message needs to be processed and stored so that they can be analysed – the individual data points may need to be retrieved to control the quality of the analysis
- The stored messages need to be analysed automatically and periodically – or at random with manual intervention
- The result of the analysis must be stored in a database where you can view it and possibly draw conclusions
The above scenario is quite generic in Big Data analysis where a large amount of possibly unstructured messages needs to be analysed. The result of the analysis must be meaningful for your business in some way. Maybe they will help you in your decision making process. Also, they can provide useful aggregation data that you can sell to your customers.
There are a number of different product offerings and possible solutions to manage such a system nowadays. We’ll go through one of them in this series.
The raw data
What kind of raw data are we talking about? Any type of textual data you can think of. It’s of course an advantage if you can give some structure to the raw data in the form of JSON, XML, CSV or other delimited data.
On the one hand you can have well-formatted JSON data that hits the entry point of your system:
{
"CustomerId": "abc123",
"DateUnixMs": 1416603010000,
"Activity": "buy",
"DurationMs": 43253
}
Alternatively the same data can arrive in other forms, such as CSV:
abc123,1416603010000,buy,43253
…or as some arbitrary textual input:
Customer id: abc123
Unix date (ms): 1416603010000
Activity: buy
Duration (ms): 43253
It is perfectly feasible that the raw data messages won’t all follow the same input format. Message 1 may be JSON, message 2 may be XML, message 3 may be formatted like this last example above.
The message handler: Kinesis
Amazon Kinesis is a highly scalable message handler that can easily “swallow” large amounts of raw messages. The home page contains a lot of marketing stuff but there’s a load of documentation available for developers, starting here.
In a nutshell:
- A Kinesis “channel” is called a stream. A stream has a name that clients can send their messages to and that consumers of the stream can read from
- Each stream is divided into shards. You can specify the read and write throughput of your Kinesis stream when you set it up in the AWS console
- A single message can not exceed 50 KB
- A message is stored in the stream for 24 hours before it’s deleted
You can read more about the limits, such as max number of shards and max throughput here. Kinesis is relatively cheap and it’s an ideal out-of-the-box entry point for big data analysis.
So let’s place the first item on our architecture diagram:

The Kinesis consumer
Kinesis stores the messages for only 24 hours and you cannot instruct it to do anything specific with the message. There are no options like “store the message in a database” or “calculate the average value” for a Kinesis stream. The message is loaded into the stream and waits until it is either auto-deleted or pulled by a consumer.
What do we mean by a Kinesis consumer? It is a listener application that pulls the messages out of the stream in batches. The listener is a worker process that continuously monitors the stream. Amazon has SDKs in a large number of languages listed here: Java, Python, .NET etc.
It’s basically any application that processes messages from a given Kinesis stream. If you’re a Java developer then there’s an out-of-the-box starting point on GitHub available here. Here’s the official Amazon documentation of the Kinesis Client Library.
On a general note: most documentation and resources regarding Amazon Web Services will be available in Java. I would recommend that, if you have the choice, then Java should be option #1 for your development purposes.
Let’s extend our diagram where I picked Java as the development platform but in practice it could be any from the available SDKs:
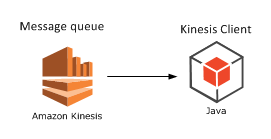
How can this application be deployed? It depends on the technology you’ve selected, but for Java Amazon Beanstalk is a straightforward option. This post gives you details on how to do it.
We’ll continue building our system with a potential raw message store mechanism in the next post: Amazon S3.
View all posts related to Amazon Web Services here.


Reblogged this on SutoCom Solutions.