HTTPS and X509 certificates in .NET Part 5: validating certificates in code
June 11, 2015 3 Comments
Introduction
In the previous post we looked at some basic classes in the .NET framework that deal with X509 certificates. We saw how to load, inspect, install and remove certificates.
In this post we’ll continue working with certificates in code and concentrate on validation techniques.
Certificate validation in C#
The two most important objects in .NET that will help you validate a certificate are X509Chain and X509ChainPolicy.
The X509Chain object represents the chain of trust when checking the validity of a certificate. X509ChainPolicy fine-tunes how you’d like to validate the certificate, i.e. which criteria the chain of trust should fulfil.
Let’s see how the self-signed certificate we created before can be validated. Consider the following sample code:
private static void RunValidation()
{
X509Store computerCaStore = new X509Store(StoreName.My, StoreLocation.LocalMachine);
try
{
computerCaStore.Open(OpenFlags.ReadOnly);
X509Certificate2Collection certificatesInStore = computerCaStore.Certificates;
X509Certificate2Collection findResult = certificatesInStore.Find(X509FindType.FindBySubjectName, "mylocalsite.local", false);
foreach (X509Certificate2 cert in findResult)
{
X509Chain chain = new X509Chain();
X509ChainPolicy chainPolicy = new X509ChainPolicy()
{
RevocationMode = X509RevocationMode.Online,
RevocationFlag = X509RevocationFlag.EntireChain
};
chain.ChainPolicy = chainPolicy;
if (!chain.Build(cert))
{
foreach (X509ChainElement chainElement in chain.ChainElements)
{
foreach (X509ChainStatus chainStatus in chainElement.ChainElementStatus)
{
Debug.WriteLine(chainStatus.StatusInformation);
}
}
}
}
}
finally
{
computerCaStore.Close();
}
}
You’ll recognise the part of this code where we open the certificate store and load the self-signed derived certificate. Note that the Find method will return a collection of X509 certificates but there’s no way to extract just a single element from a X509Certificate2Collection object. Even if you know that there’s only one certificate that fulfils the search criteria you’ll need to iterate over the collection.
Anyway, the validation part of the code starts within the foreach loop by constructing an X509Chain object. We then build a policy for the chain by specifying a couple of properties.
The RevokationMode enumeration will define whether or not we want to check the revocation list for this certificate: check it on-line, off-line or not at all. X509RevocationFlag will specify if we want to check the revocation list with or without the CA root. The X509ChainPolicy object has some more properties that will let you fine-grain the chain policy. The VerificationFlags enumeration will let you switch off parts of the chain, e.g.:
VerificationFlags = X509VerificationFlags.IgnoreInvalidName | X509VerificationFlags.IgnoreNotTimeValid
Normally you’d want to verify all properties so you’ll leave VerificationFlags untouched.
We then want to build the chain by calling the Build method with the certificate. If Build returns false then we know that something isn’t correct with the validation chain. So for each element in the chain elements we want to check the element status messages.
If you run the above code then you should get a validation error:
“The revocation function was unable to check revocation for the certificate.”
That’s because we specified that the online revocation list should be checked. However, there’s no revocation list anywhere on Earth that knows about our self-signed certificate. If we change the code to…
X509ChainPolicy chainPolicy = new X509ChainPolicy()
{
RevocationMode = X509RevocationMode.NoCheck,
RevocationFlag = X509RevocationFlag.EntireChain
};
…then the Build method passes as everything is fine with the certificate.
Open IIS for another test. We’ll use the IIS GUI to quickly create another certificate. Double-click on the following icon:

Then click on the following link in the right-hand panel:

Provide some friendly name for the certificate and click OK.
The certificate should appear in the Personal folder in the Certificates snap-in after a refresh. I called my certificate “iiscertificate”:
![]()
If you double-click this certificate then you’ll see that it is valid. Now if we change the code back to online revocation list checking…
X509ChainPolicy chainPolicy = new X509ChainPolicy()
{
RevocationMode = X509RevocationMode.Online,
RevocationFlag = X509RevocationFlag.EntireChain
};
…and search for the IIS certificate…:
X509Certificate2Collection findResult = certificatesInStore.Find(X509FindType.FindBySubjectName, "andras1.Apica.local", false);
…then Build will return true, the IIS certificate is fully trusted even after the CRL is checked.
The certificate was also inserted into the Trusted Root Certification Authorities folder:

If you don’t see it then refresh the list by pressing F5.
Now remove the certificate from the trusted CA folder. Then go back to the Personal folder and double-click the IIS certificate. You should see that it is not trusted any more:
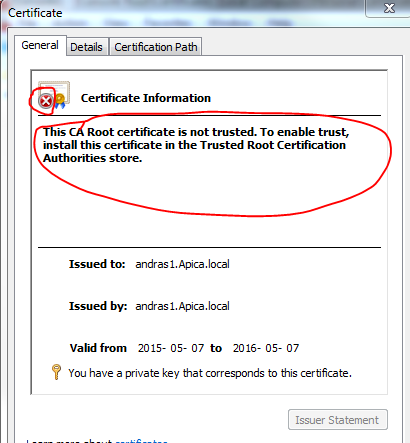
If we run the same code again then Build returns false and we get the following validation error:
“A certificate chain processed, but terminated in a root certificate which is not trusted by the trust provider.”
The message clearly says that the root certificate is not trusted.
A more compact solution
The above code lets you fine-grain your chain building logic. There are specialised X509 validators in .NET that provide a more compact way of validating a certificate. Add the following references to your project:
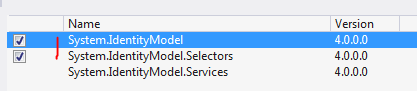
The below example will build a validator that validates the chain of trust with all the validation flags turned on:
X509CertificateValidator chainTrustValidator = X509CertificateValidator.ChainTrust;
try
{
chainTrustValidator.Validate(cert);
}
catch (Exception ex)
{
Debug.WriteLine(ex.Message);
}
The Validate method will throw an exception if the validation fails. The untrusted IIS certificate will give the following exception message:
“The X.509 certificate CN=andras1.Apica.local chain building failed. The certificate that was used has a trust chain that cannot be verified. Replace the certificate or change the certificateValidationMode. A certificate chain processed, but terminated in a root certificate which is not trusted by the trust provider.”
That’s all folks about the basics of certificate validation in .NET.
This was the last post in this HTTPS basics series.
You can view the list of posts on Security and Cryptography here.


Hello Andras, I’m trying to follow your example to validate x509 certificates, but I am having a bit of trouble. Is there a way for me to share my code with you and speak more about what I am trying to achieve?
One of the best of dozens that I’ve read.
thanks that saved my day