Introduction
In the previous post we discussed how S3 can be incorporated as a storage mechanism in our overall Big Data infrastructure. We laid out the strategy for naming and storing raw data files and folders. In this post we’ll implement this strategy in the Amazon Kinesis client demo app which we worked on in this series on Amazon Kinesis.
Have that Kinesis client demo app open in Visual Studio and let’s get to work!
Preparation
Log onto S3 and create a top bucket where all raw data files will be saved. Let’s call the bucket “raw-urls-data”.
We’ll add a couple of new methods to WebTransaction.cs of AmazonKinesisConsumer that will be used during the S3 persistence process.
Insert this private method to convert a Unix timestamp to a .NET DateTime – this will be available in C# 6 by default but we’ll need to survive with such workarounds for the time being:
private DateTime UnixTimeStampToDateTime(long unixTimeMillis)
{
DateTime epoch = new DateTime(1970, 1, 1, 0, 0, 0, 0, DateTimeKind.Utc);
DateTime converted = epoch.AddMilliseconds(unixTimeMillis);
return converted;
}
Add the following new property for easy access to the DateTime equivalent of the data point observation date:
public DateTime ObservationDateUtc
{
get
{
return UnixTimeStampToDateTime(UtcDateUnixMs);
}
}
Update the ToTabDelimitedString() method to the following:
public string ToTabDelimitedString()
{
StringBuilder sb = new StringBuilder();
string delimiter = "\t";
sb.Append(CustomerName)
.Append(delimiter)
.Append(Url)
.Append(delimiter)
.Append(WebMethod)
.Append(delimiter)
.Append(ResponseTimeMs)
.Append(delimiter)
.Append(UtcDateUnixMs)
.Append(delimiter)
.Append(ObservationDateUtc);
return sb.ToString();
}
The above modification adds the human readable UTC date to the stringified view of the raw data point.
Let’s also add one more method to the class that will form the observation date in the yyyy-MM-dd-HH-mm format. If you recall the raw data file name will follow this date format preceded by the customer name:
public string FormattedObservationDateMinutes()
{
String dateFormat = "yyyy-MM-dd-HH-mm";
return ObservationDateUtc.ToString(dateFormat);
}
We’re done with the preparations.
Strategy implementation
In the Kinesis client app we had two console applications: AmazonKinesisConsumer and AmazonKinesisProducer. Insert a new class called AmazonS3DataStorage in AmazonKinesisConsumer with the following stub implementation:
public class AmazonS3DataStorage : IRawDataStorage
{
public void Save(IEnumerable<WebTransaction> webTransactions)
{
throw new NotImplementedException();
}
}
Let’s build up this class step by step. First we’ll need to inject the top bucket name so insert the following private variable and a constructor:
private readonly string _topBucketName;
public AmazonS3DataStorage(String topBucketName)
{
if (String.IsNullOrEmpty(topBucketName)) throw new ArgumentNullException("S3 bucket name cannot be empty!");
_topBucketName = topBucketName;
}
We’ll need an object to contact S3. We’ve seen this method in the S3 series, let’s re-use it:
private IAmazonS3 GetAmazonS3Client()
{
return Amazon.AWSClientFactory.CreateAmazonS3Client(RegionEndpoint.EUWest1);
}
We’ll group the web transactions according to customer and date where the date is represented at the level of minutes. The key of the grouping – a dictionary – will be the file name format customer-year-month-day-hour-minute. The value of the dictionary will be the web transactions the customer made in that minute. The below method will create that dictionary:
private Dictionary<string, List<WebTransaction>> GroupRecordsPerCustomerAndDate(IEnumerable<WebTransaction> allWebTransactions)
{
Dictionary<string, List<WebTransaction>> group = new Dictionary<string, List<WebTransaction>>();
foreach (WebTransaction wt in allWebTransactions)
{
String key = string.Concat(wt.CustomerName, "-", wt.FormattedObservationDateMinutes());
if (group.ContainsKey(key))
{
List<WebTransaction> transactionsInGroup = group[key];
transactionsInGroup.Add(wt);
}
else
{
List<WebTransaction> transactionsInGroup = new List<WebTransaction>();
transactionsInGroup.Add(wt);
group[key] = transactionsInGroup;
}
}
return group;
}
It will be easier to follow what all these methods do later when we test the whole chain.
The following two private helper methods will build the folder name according to the folder name format we discussed in the previous post. Recall that these subfolders will represent intervals of 30 minutes:
private string BuildContainingFolderName(WebTransaction webTransaction)
{
DateTime observationDate = webTransaction.ObservationDateUtc;
int year = observationDate.Year;
string monthString = FormatDateUnitWithLeadingZeroes(observationDate.Month);
string dayString = FormatDateUnitWithLeadingZeroes(observationDate.Day);
string hourString = FormatDateUnitWithLeadingZeroes(observationDate.Hour);
int minuteInterval = GetMinuteInterval(observationDate.Minute);
string minuteIntervalString = FormatDateUnitWithLeadingZeroes(minuteInterval);
string folderNameDelimiter = "-";
return string.Concat(minuteIntervalString, folderNameDelimiter, hourString, folderNameDelimiter
, dayString, folderNameDelimiter, monthString, folderNameDelimiter, year);
}
private string FormatDateUnitWithLeadingZeroes(int dateUnit)
{
String formatted = dateUnit < 10 ? string.Concat("0", dateUnit) : dateUnit.ToString();
return formatted;
}
private int GetMinuteInterval(int minute)
{
int res = 0;
if (minute > 29)
{
res = 30;
}
return res;
}
The following helper method will build the tab delimited file content of a list of web transactions:
private String BuildRawDataFileContent(List<WebTransaction> webTransactions)
{
StringBuilder recordBuilder = new StringBuilder();
int size = webTransactions.Count;
for (int i = 0; i < size; i++)
{
recordBuilder.Append(webTransactions[i].ToTabDelimitedString());
if (i < size - 1)
{
recordBuilder.Append(Environment.NewLine);
}
}
return recordBuilder.ToString();
}
…and this one will save the web transaction objects in an S3 folder:
private void SaveWebTransactionsInFolder(string folderName, string fileKey, List<WebTransaction> webTransactionsInFile)
{
string fileContents = BuildRawDataFileContent(webTransactionsInFile);
using (IAmazonS3 s3Client = GetAmazonS3Client())
{
try
{
PutObjectRequest putObjectRequest = new PutObjectRequest();
putObjectRequest.ContentBody = fileContents;
String delimiter = "/";
putObjectRequest.BucketName = string.Concat(_topBucketName, delimiter, folderName);
putObjectRequest.Key = fileKey;
PutObjectResponse putObjectResponse = s3Client.PutObject(putObjectRequest);
}
catch (AmazonS3Exception e)
{
Console.WriteLine("Failed to save the raw data observations in S3.");
Console.WriteLine("Amazon error code: {0}",
string.IsNullOrEmpty(e.ErrorCode) ? "None" : e.ErrorCode);
Console.WriteLine("Exception message: {0}", e.Message);
}
}
}
There’s only one method missing before completing the Save method. This helper method will check if the required folder is present in the top bucket. If yes then it will call the above method to save the raw data. Otherwise the method will create the folder first and then save the raw data. Insert the following method:
private void SaveInS3(String fileKey, List<WebTransaction> webTransactions)
{
if (!fileKey.EndsWith(".txt"))
{
fileKey += ".txt";
}
WebTransaction first = webTransactions.First();
string containingFolder = BuildContainingFolderName(first);
//check if folder exists
using (IAmazonS3 s3Client = GetAmazonS3Client())
{
try
{
ListObjectsRequest findFolderRequest = new ListObjectsRequest();
findFolderRequest.BucketName = _topBucketName;
findFolderRequest.Delimiter = "/";
findFolderRequest.Prefix = containingFolder;
ListObjectsResponse findFolderResponse = s3Client.ListObjects(findFolderRequest);
List<string> commonPrefixes = findFolderResponse.CommonPrefixes;
if (commonPrefixes.Any())
{
SaveWebTransactionsInFolder(containingFolder, fileKey, webTransactions);
}
else //need to create S3 bucket first
{
PutObjectRequest folderRequest = new PutObjectRequest();
folderRequest.BucketName = _topBucketName;
string delimiter = "/";
String folderKey = string.Concat(containingFolder, delimiter);
folderRequest.Key = folderKey;
folderRequest.InputStream = new MemoryStream(new byte[0]);
PutObjectResponse folderResponse = s3Client.PutObject(folderRequest);
SaveWebTransactionsInFolder(containingFolder, fileKey, webTransactions);
}
}
catch (AmazonS3Exception e)
{
Console.WriteLine("Folder existence check or folder creation has failed.");
Console.WriteLine("Amazon error code: {0}",
string.IsNullOrEmpty(e.ErrorCode) ? "None" : e.ErrorCode);
Console.WriteLine("Exception message: {0}", e.Message);
}
}
}
We can now complete the body of the Save method:
public void Save(IEnumerable<WebTransaction> webTransactions)
{
Dictionary<string, List<WebTransaction>> groups = GroupRecordsPerCustomerAndDate(webTransactions);
foreach (var kvp in groups)
{
try
{
if (groups.Values.Any())
{
SaveInS3(kvp.Key, kvp.Value);
}
}
catch (Exception ex)
{
Console.WriteLine(string.Concat("Failed to write web transactions in ", kvp.Key, " to the S3 bucket"));
}
}
}
We group the observations and then save the raw data for each group.
Test
Currently we save the raw data to a file using the FileBasedDataStorage implementation of IRawDataStorage in Program.cs of AmazonKinesisConsumer within the ReadFromStream method. Replace it with the following:
IRawDataStorage rawDataStorage = new AmazonS3DataStorage("raw-urls-data");
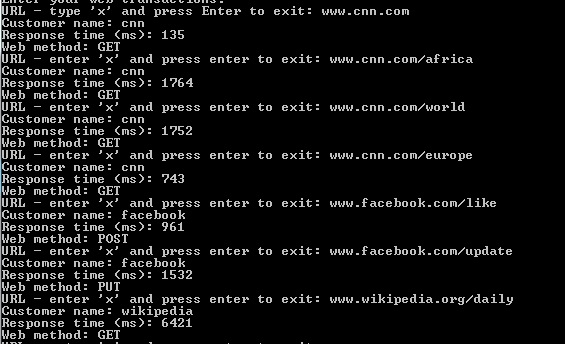
Start AmazonKinesisProducer and send several URL observations to Kinesis. Make sure to send at least 2 for the same customer to check if they are really saved in the same file. I’m sending the following data points:

Start the AmazonKinesisConsumer application and the data points should be caught and processed. It’s a good idea to put break points here and there to be able to follow what’s happening exactly. In my case the data points ended up in S3 as follows:

The above image shows other test values as well but the data points shown in the above console image all ended up in the 00-21-12-12-2014 folder, i.e. their observation date properties all lie within the 21:00 – 21:30 interval of December 12 2014. Let’s see the contents of that folder:

You can see that the file naming convention follows what we have planned: customer-year-month-day-hour-minute UTC. The interpretation of the top item, i.e. cnn-2014-12-12-21-18.txt is that customer CNN made the following calls during 21:18, i.e. from 21:18:00 to 21:18:59 on December 12 2014. The actual calls are shows within the file as follows:
cnn http://www.cnn.com GET 135 1418419114682 2014-12-12 21:18:34
cnn http://www.cnn.com/africa GET 1764 1418419125964 2014-12-12 21:18:45
You can find both data points in the screenshot above.
Current status
Currently we have the working skeleton project of the following Big Data system:
- A message handling system that can process a very large amount of messages per second, i.e Amazon Kinesis
- Code that can accept, validate and store the raw data points in a human and machine readable format
- A durable and flexible storage mechanism in Amazon S3 where humans can find individual data points and external systems can extract data from
Possible improvements
Apart from obvious software engineering considerations, such as SOLID, DRY, layering etc. we can introduce a couple improvements to the code, e.g.:
- The code checks in every loop if a specific folder exists in S3. This can be sped up by putting the folder names created into the cache and first check the contents of the cache. The save process must be as quick as possible and checking for the presence of a folder unnecessarily slows down the performance
- Don’t assume that you can anticipate the order of the messages coming in from Kinesis. They are sent in batches and it is possible that two data points that should be saved in the same raw data file in S3 will come in two different batches. The result will be that the code will throw an exception when the second message is saved as there’s already a file with the required name. You could check for the existence of the file and extend its contents but that really slows down the performance. There’s no built-in update mechanism in S3 – you have to download the contents of the file, append the new content to it, delete the original file and upload a new one. Instead we can go with an extended naming convention for the raw data files and add a unique identifier to each batch from Kinesis, like a GUID or something similar. We’ll then go with the file name format of customer-year-month-day-hour-minute-batchnumber.txt.
Next step
This post concludes our discussion of Amazon S3 in .NET. The next series will look at another storage mechanism offered by Amazon: DynamoDb which is Amazon’s take on the NoSql world. We’ll discuss this database solution and see how it can fit into a cloud based Big Data architecture.
View all posts related to Amazon Web Services and Big Data here.