Introduction to CouchDB with .NET part 9: starting with view design documents
June 2, 2017 1 Comment
Introduction
In the previous post we looked at data replication in CouchDB. Data replication means that the documents of a source database are copied over to the target database. At the end of the replication process the source and target databases should have the exact same set of documents where even the revision IDs are the same. Data replication is a means of creating backups and archives. It is also great if we need to test a function on real-life production data. We can run the tests on the replicated data set as much as we want without any effect on the production system. Data replication can be a one-off event or a continuous flow of data synchronisation.
In this post we’ll start looking into a large topic within CouchDB, namely design documents.
Design documents
Design documents are JSON documents in CouchDB just like any data document we’ve seen so far. However, they have a special purpose and are also treated separately from normal documents. There’s also a separate section for them in the Fauxton UI:

Design documents must, however, adhere to a set of rules as to what properties they have. They contain instructions that are applied on the database where they reside. Design documents can be grouped into the following categories depending on their purpose:
- View: CouchDB views are similar to views in SQL databases. Views are used to create a new data set out of a set of documents without creating a separate database for it. With views we can perform things like grouping, aggregating, sorting, i.e. mostly stuff that we do with T-SQL in a relational database like MS SQL Server. Views also provide an entry into querying CouchDB documents.
- Validation: data validation of the documents when creating new documents
- Update: trigger an update of certain documents
- Show & List: transform the documents
Each type has a specific declaration in the design document JSON. E.g. the section where all views are contained is called “views”, the section for shows and lists is called “shows”. A single design document can contain many of each type but it’s a good idea to create several design documents with a specific purpose.
Design documents contain JavaScript functions for their logic. They can be confusing at first since the JS functions are embedded within a JSON structure. Design documents are stored in a special container called “_design” within a database. They also have IDs like data documents but design document ID names must be prefixed with “_design”.
MapReduce
Another concept that is strongly connected to design documents is MapReduce or MapFilterReduce.
MapReduce is eagerly used in data mining and big data applications to extract information from a large, potentially unstructured data set. E.g. finding the average age of all Employees who have been employed for more than 5 years is a good candidate for this algorithm.
The individual parts of Map/Filter/Reduce, i.e. the Map, the Filter and the Reduce are steps or operations in a chain to compute something from a collection. Not all 3 steps are required in all data mining cases. Basic examples:
- Finding the average age of employees who have been working at a company for more than 5 years: you map the age property of each employee to a list of integers but filter out those who have been working for less than 5 years. Then you calculate the average of the elements in the integer list, i.e. reduce the list to a single outcome.
- Finding the ids of every employee: if the IDs are strings then you can map the ID fields into a list of strings, there’s no need for any filtering or reducing.
- Finding the average age of all employees: you map the age of each employee into an integer list and then calculate the average of those integers in the reduce phase, there’s no need for filtering
- Find all employees over 50 years of age: we filter out the employees who are younger than 50, there’s no need for mapping or reducing the employees collection.
MapReduce implementations in reality can become quite complex depending on the query and structure of the source data. They are heavily used in CouchDB querying and seem very strange at first compared to how we normally perform queries in other databases with SELECT statements. Also, the most popular NoSql database MongoDb provides an easy way to query the data with its find JavaScript function and JSON based query statements. CouchDB has taken a different approach, at least up until version 2.
In fact, the need for views and MapReduce for queries has probably proved too off-putting for many newcomers to CouchDB. As a response CouchDB 2 introduced a new query language called Mango which was heavily influenced by the MongoDb find function. We’ll check it out in a later post. It’s still a very important step to get to know design documents in CouchDB since they provide a lot of functionality and the Mango query language is not available in earlier versions of CouchDB. Therefore if you get involved with a project that uses CouchDB 1 as its data store then views will be the only means for querying.
Views and indexes
As mentioned above views are the primary means of querying in CouchDB. An important thing to keep in mind is that there’s no way to perform ad-hoc queries with views. There’s no way to just implement a query statement like “select all product names in the category furniture whose primary colour is brown and are out of stock right now”. You’ll need to think about your queries up front and declare them in views as MapReduce functions. I know what this sounds like but please don’t stop reading now :-). We’ll go through a number of examples. You can make up your mind afterwards.
Let’s jump right into it and create our first view. Create a new database called children, either via the HTTP API or the Fauxton UI, it doesn’t matter. Add the following documents to it:
{
"_id": "8a6469af31cb8032e49c2e66480004fd",
"first_name": "John",
"last_name": "Williams",
"gender": "m",
"age": 6
}
{
"_id": "8a6469af31cb8032e49c2e6648000e92",
"first_name": "Sophia",
"last_name": "Jones",
"gender": "f",
"age": 7
}
{
"_id": "8a6469af31cb8032e49c2e6648001c23",
"first_name": "Richard",
"last_name": "Brown",
"gender": "m",
"age": 5
}
{
"_id": "8a6469af31cb8032e49c2e6648002bc3",
"first_name": "Emily",
"last_name": "Davies",
"gender": "f",
"age": 6
}
{
"_id": "8a6469af31cb8032e49c2e6648002c80",
"first_name": "Daniel",
"last_name": "Roberts",
"gender": "m",
"age": 7
}
{
"_id": "8a6469af31cb8032e49c2e6648003a3e",
"first_name": "Olivia",
"last_name": "Walker",
"gender": "f",
"age": 8
}
Now click on the + icon to the right of Design Documents in Fauxton and select New View. You’ll be presented with the following form:

Design Document will be “New document” since we want to create a new document. This is currently the only option we can select as we have no other design documents yet. To the right of that field we have to enter an ID for the document. As mentioned above design document IDs are prefixed with the “_design” keyword. Enter “query-demo” in the text field.
Then we have an index name. If a view is executed on a set of documents then a result is returned and stored separately from the documents sorted by the key. We’ll soon see what the key is. This result from running a view is an index in CouchDB. If the documents in the database are updated and the view is executed again then the result set is updated and hence the index is also updated.
A single design document can include many views and each view in the document is associated with a view index that are then stored together in a group. This group of indexes belongs to the same design document. If we execute any view within this group of views then the entire view result set is updated, meaning all indexes are updated in case there’s been a change in the data documents of the database. In that sense views within a design document move together as a unit. Since it can take time to update the indexes it’s a good idea to keep the view design documents small.
For this demo enter “full-name” as the index name.
Next up is the map function. The name “map” will sound familiar from the MapReduce intro above and that’s exactly what we’re achieving here with the map function: we implement the map phase of MapReduce. Map is a JavaScript function. Look at the default function provided by the Fauxton UI:
function (doc) {
emit(doc._id, 1);
}
The map phase is always a function that accepts a data document. Map will iterate through each document in the database and apply this function on it. “Emit” is sort of a return statement which accepts two parameters: a key and a value. Let’s keep the default function to begin with and see what it does. We’ll update it later.
Finally we have the Reduce step which obviously corresponds to “reduce” in MapReduce. You can expand the drop-down list to see the default options. There are three built-in reducers called _sum, _count and _stats where _sum and _count will most certainly sound familiar from T-SQL. We’ll leave this option at NONE to begin with. So this is what we have as the first view:

Click on the Create Document and Build Index button. The index will be available in the Fauxton UI. You can click on it to see what it returns:
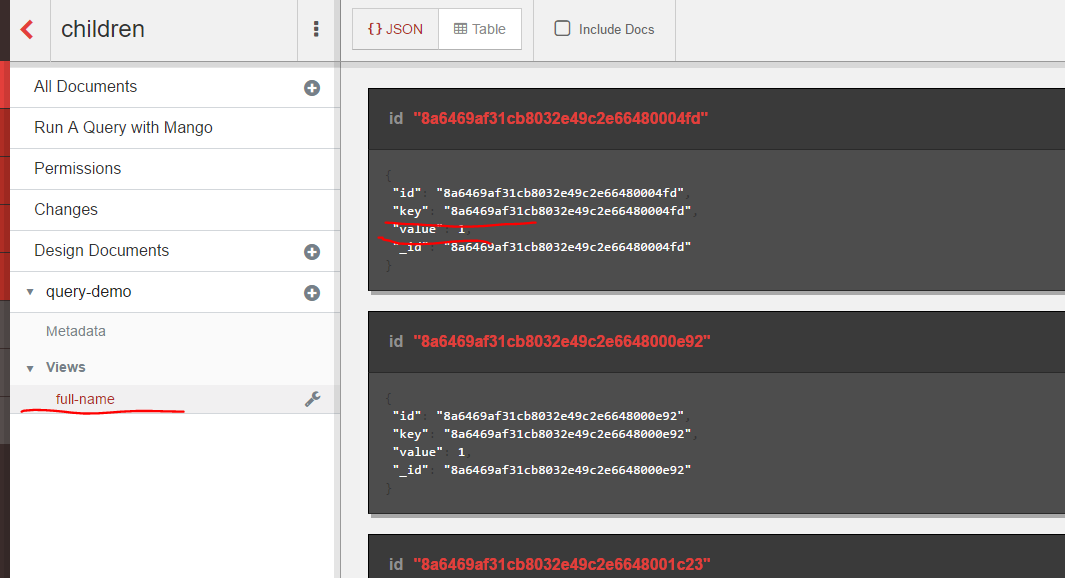
We have the “key” and “value” fields that were returned – or emitted, as it’s called in the map function – from the view. It’s not much but at least it’s simple to follow what happened. Since we didn’t apply any filter the map function returned all documents, set the key as the document ID and the value simply as an integer 1. That’s what the emit(doc._id, 1) statement means: the first argument is the key, i.e. the document ID and the second is the value. It’s difficult to see with the long ID fields but the resulting documents are sorted by the keys in ascending alphabetical order.
One thing to note here is how a view can be reached via the URL. When we clicked on the index name the URL in the browser was updated to the following:
http://localhost:5984/_utils/#/database/children/_design/query-demo/_view/full-name
So within the database “children” we have the special “_design” container, followed by the design document name, “query-demo” in this case. We want to look at the views within the this design document, and specifically the view whose index is called “full-name”.
We can look at the JSON representation of this design document via the following GET query:
GET http://localhost:5984/children/_design/query-demo
It returns the structure of the design document as follows:
{
"_id": "_design/query-demo",
"_rev": "1-c8cd8d805566c54484bb56cb327d9a98",
"views": {
"full-name": {
"map": "function (doc) { emit(doc._id, 1);}"
}
},
"language": "javascript"
}
As noted before the views in a design document are denoted by the “views” keyword. That’s a special section within a design document, it must be called “views”. The views section includes all the indexes we have. You’ll recognise our full-name index with its simple JS function. It’s important to be familiar with the JSON representation of design documents since the HTTP API offers a wide range of operations related to them through the /database/_design/ endpoint. We’ll test some of them later on.
Now let’s return to Fauxton and update our index:
![]()
Insert the following JS function as the map phase:
function (doc) {
emit(doc.last_name, doc.first_name + ' ' + doc.last_name);
}
We now return the last name as the key and the full name as the value. Let’s execute this view via the HTTP API this time:
GET http://localhost:5984/children/_design/query-demo/_view/full-name
We get the following result set:
{
"total_rows": 6,
"offset": 0,
"rows": [
{
"id": "8a6469af31cb8032e49c2e6648001c23",
"key": "Brown",
"value": "Richard Brown"
},
{
"id": "8a6469af31cb8032e49c2e6648002bc3",
"key": "Davies",
"value": "Emily Davies"
},
{
"id": "8a6469af31cb8032e49c2e6648000e92",
"key": "Jones",
"value": "Sophia Jones"
},
{
"id": "8a6469af31cb8032e49c2e6648002c80",
"key": "Roberts",
"value": "Daniel Roberts"
},
{
"id": "8a6469af31cb8032e49c2e6648003a3e",
"key": "Walker",
"value": "Olivia Walker"
},
{
"id": "8a6469af31cb8032e49c2e66480004fd",
"key": "Williams",
"value": "John Williams"
}
]
}
The result set was automatically sorted by the key, i.e. the last name. The value was set to the full name of each child.
OK, that should be enough for the moment. Let it all sink in and we’ll continue in the next post.
You can view all posts related to data storage on this blog here.


Pingback: CouchDB Weekly News, June 8, 2017 – CouchDB Blog