Using Amazon Elastic MapReduce with the AWS .NET API Part 5: cluster-related code
March 2, 2015 3 Comments
Introduction
In the previous post we looked at some basic Hive and Hadoop commands. We created a database for the URLs and a table which stores URLs and response times. Finally we executed an aggregation function on the table data and stored the results in another table.
So far in this series we haven’t seen any C# code. It’s time to rectify that. We’ll see a couple of cluster-related examples such as finding the clusters and starting a new one.
Note that we’ll be concentrating on showing and explaining the technical code examples related to AWS. We’ll ignore software principles like SOLID and layering so that we can stay focused. It’s your responsibility to organise your code properly. There are numerous posts on this blog that take up topics related to software architecture.
Installing the SDK
The Amazon .NET SDK is available through NuGet. Open Visual Studio 2012/2013 and create a new C# console application called ElasticMapReduceDemo. The purpose of this application will be to demonstrate the different parts of the SDK around EMR. In reality the EMR handler could be any type of application:
- A website
- A Windows/Android/iOS app
- A Windows service
- etc.
…i.e. any application that’s capable of sending HTTP/S requests to a web service endpoint. We’ll keep it simple and not waste time with view-related tasks.
Install the following NuGet package:

Preparations
We cannot just call the services within the AWS SDK without proper authentication. This is an important reference page to handle your credentials in a safe way. We’ll the take the recommended approach and create a profile in the SDK Store and reference it from app.config.
This series is not about AWS authentication so we won’t go into temporary credentials but later on you may be interested in that option too. Since we’re programmers and it takes a single line of code to set up a profile we’ll go with the programmatic options. Add the following line to Main:
Amazon.Util.ProfileManager.RegisterProfile("demo-aws-profile", "your access key id", "your secret access key");
I suggest you remove the code from the application later on in case you want to distribute it. Run the application and it should execute without exceptions. Next open app.config and add the appSettings section with the following elements:
<appSettings>
<add key="AWSProfileName" value="demo-aws-profile"/>
</appSettings>
Storing the EMR handle
We’ll put all our test code into a separate class. Insert a cs file called EmrDemoService. We’ll need a method to build a handle to the service which is of type IAmazonElasticMapReduce:
private IAmazonElasticMapReduce GetEmrClient()
{
return Amazon.AWSClientFactory.CreateAmazonElasticMapReduceClient(RegionEndpoint.EUWest1);
}
Note that we didn’t need to provide our credentials here. They will be extracted automatically using the profile name in the config file.
Get clusters list
public List<ClusterSummary> GetClusterList()
{
using (IAmazonElasticMapReduce emrClient = GetEmrClient())
{
try
{
ListClustersResponse listClustersResponse = emrClient.ListClusters();
List<ClusterSummary> clusters = listClustersResponse.Clusters;
Console.WriteLine(string.Format("Found {0} EMR clusters.", clusters.Count));
foreach (ClusterSummary cluster in clusters)
{
Console.WriteLine(string.Format("Cluster id: {0}, cluster name: {1}, cluster status: {2}",
cluster.Id, cluster.Name, cluster.Status.State));
}
return clusters;
}
catch (AmazonElasticMapReduceException emrException)
{
Console.WriteLine("Cluster list extraction has failed.");
Console.WriteLine("Amazon error code: {0}",
string.IsNullOrEmpty(emrException.ErrorCode) ? "None" : emrException.ErrorCode);
Console.WriteLine("Exception message: {0}", emrException.Message);
throw;
}
}
}
Call from Main:
static void Main(string[] args)
{
EmrDemoService emrDemoService = new EmrDemoService();
emrDemoService.GetClusterList();
Console.WriteLine("Main done...");
Console.ReadKey();
}
If you followed along the series so far then you might get 1 or more terminated instances:
Found 2 EMR clusters.
Cluster id: j-3ZUB7Z727QPS, cluster name: My cluster, cluster status: TERMINATED
Cluster id: j-3ILS4ATXBUI3M, cluster name: Test cluster, cluster status: TERMINATED
Note that the cluster IDs start with a “j” which stands for “job”. It’s important to note the difference between a “job” and a “step” in EMR. A job is an overall EMR activity which can have 1 or more steps. A step is an activity within a job, like “install Hive” or “run a Hive script”. So a job is a collection of steps. A job is complete once all its steps have been completed, whether with or without exceptions. Step IDs start with an “s”. You can see those on the EMR dashboard which shows how the steps are progressing, like “pending”, “running” and “completed”.
Starting a cluster and terminating it in code
We’ve seen that there are many things to consider before starting an EMR cluster. Think of the sections on the EMR GUI. We need to specify the EC2 instance types, security, logging, the steps, the tags etc. So no wonder that the code to start a cluster, i.e. a job, is also relatively long with lots of steps. Add the following method to EmrDemoService:
public void StartCluster()
{
using (IAmazonElasticMapReduce emrClient = GetEmrClient())
{
try
{
List<ClusterSummary> clusters = GetClusterList();
List<ClusterSummary> activeWaitingClusters = (from c in clusters where c.Status.State.Value.ToLower() == "waiting" select c).ToList();
if (!activeWaitingClusters.Any())
{
StepFactory stepFactory = new StepFactory(RegionEndpoint.EUWest1);
StepConfig enableDebugging = new StepConfig()
{
Name = "Enable debugging",
ActionOnFailure = "TERMINATE_JOB_FLOW",
HadoopJarStep = stepFactory.NewEnableDebuggingStep()
};
StepConfig installHive = new StepConfig()
{
Name = "Install Hive step",
ActionOnFailure = "TERMINATE_JOB_FLOW",
HadoopJarStep = stepFactory.NewInstallHiveStep(StepFactory.HiveVersion.Hive_Latest)
};
StepConfig installPig = new StepConfig()
{
Name = "Install Pig step",
ActionOnFailure = "TERMINATE_JOB_FLOW",
HadoopJarStep = stepFactory.NewInstallPigStep()
};
JobFlowInstancesConfig jobFlowInstancesConfig = new JobFlowInstancesConfig()
{
Ec2KeyName = "your-iam-key",
HadoopVersion = "2.4.0",
InstanceCount = 3,
KeepJobFlowAliveWhenNoSteps = true,
MasterInstanceType = "m3.xlarge",
SlaveInstanceType = "m3.xlarge",
TerminationProtected = true
};
List<Tag> tags = new List<Tag>();
tags.Add(new Tag("Environment", "Test"));
tags.Add(new Tag("Library", ".NET"));
RunJobFlowRequest runJobFlowRequest = new RunJobFlowRequest()
{
Name = "EMR cluster creation demo",
Steps = { enableDebugging, installHive, installPig },
LogUri = "s3://log",
Instances = jobFlowInstancesConfig,
Tags = tags,
};
RunJobFlowResponse runJobFlowResponse = emrClient.RunJobFlow(runJobFlowRequest);
String jobFlowId = runJobFlowResponse.JobFlowId;
Console.WriteLine(string.Format("Job flow id: {0}", jobFlowId));
bool oneStepNotFinished = true;
while (oneStepNotFinished)
{
DescribeJobFlowsRequest describeJobFlowsRequest = new DescribeJobFlowsRequest(new List<string>() { jobFlowId });
DescribeJobFlowsResponse describeJobFlowsResponse = emrClient.DescribeJobFlows(describeJobFlowsRequest);
JobFlowDetail jobFlowDetail = describeJobFlowsResponse.JobFlows.First();
List<StepDetail> stepDetailsOfJob = jobFlowDetail.Steps;
List<string> stepStatuses = new List<string>();
foreach (StepDetail stepDetail in stepDetailsOfJob)
{
StepExecutionStatusDetail status = stepDetail.ExecutionStatusDetail;
String stepConfigName = stepDetail.StepConfig.Name;
String statusValue = status.State.Value;
stepStatuses.Add(statusValue.ToLower());
Console.WriteLine(string.Format("Step config name: {0}, step status: {1}", stepConfigName, statusValue));
}
oneStepNotFinished = stepStatuses.Contains("pending") || stepStatuses.Contains("running");
Thread.Sleep(10000);
}
SetTerminationProtectionRequest setProtectionRequest = new SetTerminationProtectionRequest();
setProtectionRequest.JobFlowIds = new List<string> { jobFlowId };
setProtectionRequest.TerminationProtected = false;
SetTerminationProtectionResponse setProtectionResponse = emrClient.SetTerminationProtection(setProtectionRequest);
TerminateJobFlowsRequest terminateRequest = new TerminateJobFlowsRequest(new List<string> { jobFlowId });
TerminateJobFlowsResponse terminateResponse = emrClient.TerminateJobFlows(terminateRequest);
Console.WriteLine(string.Format("Termination HTTP status code: {0}", terminateResponse.HttpStatusCode));
}
}
catch (AmazonElasticMapReduceException emrException)
{
Console.WriteLine("Cluster list creation has failed.");
Console.WriteLine("Amazon error code: {0}",
string.IsNullOrEmpty(emrException.ErrorCode) ? "None" : emrException.ErrorCode);
Console.WriteLine("Exception message: {0}", emrException.Message);
}
}
}
Let’s go through this step by step:
- We first check whether we have any clusters in status “waiting”, i.e. clusters that are free to take on one or more steps. If not then we start the job creation process
- Each step is defined by a StepConfig object. We define 3 steps to be completed in the job
- The steps are: enable debugging, install Hive and install Pig. If one step fails then we want to terminate the job
- Each step can be defined using a step factory which returns out-of-the-box definitions of common steps, like Hive and Pig installation. For Hive we can even specify the Hive version to be installed in an enumeration. Step factory includes other step types like “run Hive script” or “run Pig script”
- After the step configuration we define the instances. The Ec2KeyName property defines the name of the security key which you used to log into the master node. Provide its name as a string
- We’ll need 3 instances: they will be divided up as 1 master node and 2 slave nodes
- KeepJobFlowAliveWhenNoSteps indicates whether we want the cluster to continue running after each step has been completed
- We also specify the Ec2 instance types here and whether the cluster is protected from termination
- After the instances we specify a couple of tags
- We tie all these elements together in a RunJobFlowRequest objects. We give it a name, the steps to be carried out, a log URI in S3 – which is optional – , the tags and the instances
- We then ask the Emr client to run the job. If everything goes well then we get a Job id back which can look like j-3T2YZG4I1A4NV
After all these steps we continue to poll the job status until all steps have completed either with or without exceptions. We use the DescribeJobFlowsRequest to define the job flow ID which we want to check. We only have one so we take the first JobFlowDetail object of the DescribeJobFlowsResponse object that the Emr client returned. We then check the status of each step in the job with an interval of 10 seconds. We print their statuses and wait until they are in a status other than “pending” or “running”.
After the steps have completed we revoke the termination protection and terminate the job.
Note that in order for the above code to work your AWS user must be authorised to start EC2 instances. You’ll get an Amazon exception if that’s not the case so you’ll know. The IAM portal is used to define what a user or user group is allowed to do in AWS. The policies are defined as JSON strings:

If your user lacks EC2 rights you can extend this JSON using the “Manage policy” link in the same row. An EC2 policy which allows all operations can look like this:
{
“Sid”: “Stmt1410436730000”,
“Effect”: “Allow”,
“Action”: [
“ec2:*”
],
“Resource”: [
“*”
]
}
Call from Main:
static void Main(string[] args)
{
EmrDemoService emrDemoService = new EmrDemoService();
emrDemoService.StartCluster();
Console.WriteLine("Main done...");
Console.ReadKey();
}
You can monitor the progress in the EMR dashboard also and check if the values, like the tags and job flow name are correct:
![]()
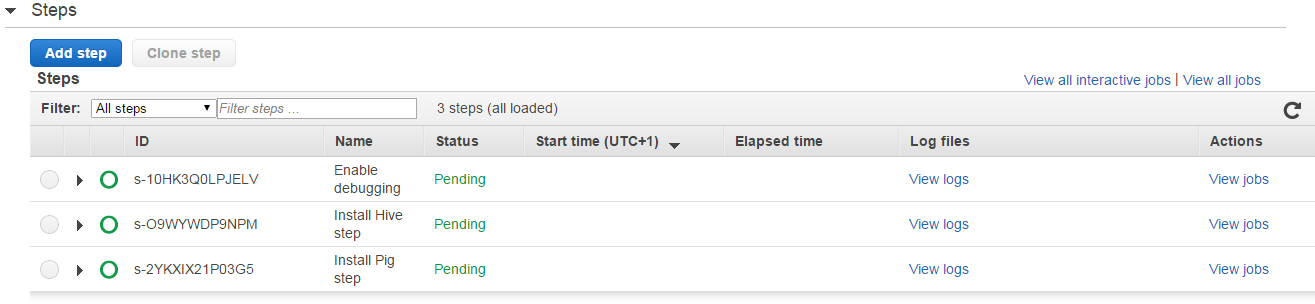
In the console you’ll first see the PENDING statuses:

The steps are finally all complete:
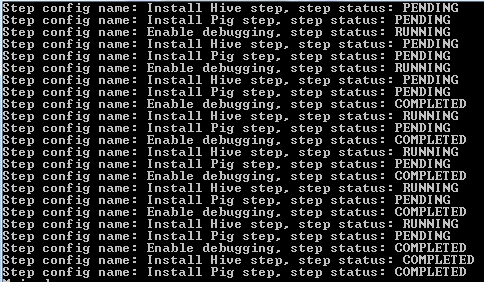
The status of the cluster briefly switches to “waiting” when it receives the termination request from our console application.
That’s enough for now. We’ll return to the Hive CLI in the next post to see how EMR can interact with S3 and DynamoDb.
View all posts related to Amazon Web Services and Big Data here.


Reblogged this on Brian By Experience.
Reblogged this on SutoCom Solutions.
Hello,
Nice artical.
Can you bit explain how we can resize cluster on the basis of memory ,disk space.when we don,t have enough space and memory in core node add one more core node when we have space and memory and still processing add more task node. Once the processing is over terminate these extra nodes core and task.