Test Driven Development in .NET Part 4: Refactoring
April 4, 2013 Leave a comment
In this post we’ll look closer at the Refactor step of the TDD cycle. Refactoring means changing the internal implementation of a method or a class without changing the way the class can be consumed by others. In other words Refactoring shouldn’t involve changing the signatures of public methods, the name of the class, the existing constructors, i.e. anything that can be used externally. The changes you make should not break the code of the consumers of the class. These consumers include the tests as well, they should not be affected by the changes either.
The benefit of having the tests in place is that you can easily check if the functions still work as they should after refactoring.
Why refactor???
What is all this fuss about refactoring? We wrote a failing test, then made it pass, implemented the method under test so we should be done, right? Not quite. This may be true of some extremely simple methods, like adding two numbers. In real life applications if you leave your code unattended after the first refactoring cycle then eventually it will very likely grow into a monster over time due to the lack of maintenance. Unless you always write perfectly S.O.L.I.D. code all the time of course, in which case you can stop reading this post.
Think of everyday objects, such as a bicycle. You buy a bike and you may think: I can ride my bicycle every day forever after without any worries. In reality you will have to tend to your bike: oil the chain, change and pump the tires, remove the rust etc. If you don’t maintain your bike then it will decay over time. This is true of many other objects: cars, houses, computers etc., they all need regular maintenance and refinement. The code you write is also such an object. You cannot let it “rust”, you need to come back to it and ask some questions: does it perform well during stress testing? Is the method trying to achieve too much? Does it follow the Single Responsibility Principle? Can I break it down into smaller methods that each carries out one thing at a time?
The following questions are just as important: are you going to understand your code when you come back to it after a year? Is it easy to follow? Is it well documented? Is the documentation up to date?
Proper refactoring ensures that the answer to the questions is yes, or at least a lot closer to ‘yes’ than without refactoring.
You may not always have the time to refactor your code and write unit tests. Developers are often pressed by deadlines, emergency bug fixes, change requests and the like. In that case you may cut corners by forgetting about TDD altogether. Keep in mind though that you will have to repay the short term time gain in the long term with interest. The extra time you will need later comes in different forms: time spent trying to understand the code, trying to change the code, fixing the new bugs that show up due to the lack of tests.
How to refactor?
We will build on the Calculator project we started in the previous post. We’ll expand it to make it a bit more complex as it’s difficult to meaningfully refactor the extremely simple methods and classes the project currently has.
Add the following folder and files to Calculator.Domain:

Here comes the content of each file:
Aggregator.cs:
public class Aggregator
{
private readonly IList<Observation> _observations;
public Aggregator(IList<Observation> observations)
{
_observations = observations;
}
public IEnumerable<Observation> Aggregate(IPartitioner partitioner,
ICalculator calculator)
{
var partitions = partitioner.Partition(_observations);
foreach (var partition in partitions)
{
yield return calculator.AggregateCollection(partition);
}
}
}
AveragingCalculator.cs:
public class AveragingCalculator : ICalculator
{
public Observation AggregateCollection(IEnumerable<Observation> observations)
{
return new Observation()
{
HighValue = observations.Average(m => m.HighValue),
LowValue = observations.Average(m => m.LowValue)
};
}
}
DefaultPartitioner.cs:
public class DefaultPartitioner : IPartitioner
{
private readonly int _size;
public DefaultPartitioner(int size)
{
_size = size;
}
public IEnumerable<IEnumerable<Observation>> Partition(IList<Observation> observations)
{
int total = 0;
while (total < observations.Count)
{
yield return observations.Skip(total).Take(_size);
total += _size;
}
}
}
ICalculator.cs:
public interface ICalculator
{
Observation AggregateCollection(IEnumerable<Observation> observations);
}
IPartitioner.cs:
IEnumerable<IEnumerable<Observation>> Partition(IList<Observation> observations);
ModalCalculator.cs:
public Observation AggregateCollection(IEnumerable<Observation> observations)
{
double highValue = observations.GroupBy(m => m.HighValue)
.OrderByDescending(g => g.Count())
.Select(g => g.Key).FirstOrDefault();
double lowValue = observations.GroupBy(m => m.LowValue)
.OrderByDescending(g => g.Count())
.Select(g => g.Key).FirstOrDefault();
return new Observation()
{
HighValue = highValue,
LowValue = lowValue
};
}
Observation.cs:
public class Observation
{
public double HighValue { get; set; }
public double LowValue { get; set; }
}
Processor.cs:
public IEnumerable<Observation> LoadData()
{
List<Observation> observationList = new List<Observation>();
XDocument document = XDocument.Load("observations.xml");
foreach (XElement element in document.Element("Observations").Elements())
{
double highValue = (double)element.Attribute("High");
double lowValue = (double)element.Attribute("Low");
Observation observation = new Observation();
observation.HighValue = highValue;
observation.LowValue = lowValue;
observationList.Add(observation);
}
Aggregator aggregator = new Aggregator(observationList);
IPartitioner partitioner = new DefaultPartitioner(2);
ICalculator calculator = new AveragingCalculator();
IEnumerable<Observation> observations = aggregator.Aggregate(partitioner, calculator);
return observations;
}
Add a console application to the solution called Calculator.Main and add a reference to Calculator.Domain. Program.cs will look like this:
static void Main(string[] args)
{
Processor processor = new Processor();
IEnumerable<Observation> observations = processor.LoadData();
foreach (Observation o in observations)
{
Console.WriteLine("{0}:{1}", o.LowValue, o.HighValue);
}
Console.ReadLine();
}
Add an XML file to Calculator.Main called observations.xml:
<?xml version="1.0" encoding="utf-8" ?> <Observations> <Observation High="10" Low="3"/> <Observation High="11" Low="10"/> <Observation High="13" Low="8"/> <Observation High="15" Low="7"/> <Observation High="16" Low="5"/> <Observation High="11" Low="4"/> <Observation High="12" Low="3"/> </Observations>
Select observations.xml in the Solution Explorer and press Alt+Enter. In the Properties window select ‘Content’ for Build Action and ‘Copy if newer’ for Copy To Output Directory.
Run the project to make sure it compiles and works. You should get the below output:
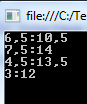
I will not go through the code in detail here as it is not our focus. Step through the code step by step using breakpoints and F11, it should be easy to follow.
How to refactor?
We will concentrate on Processor.cs and its LoadData() method. We pretend that we inherited this method from another developer. After all, you would not write anything like this, right? It’s only those other developers that don’t keep testability in mind who would put together such a method.
It’s an antithesis to the Single Responsibility Principle, although there are certainly a lot worse examples out there. We can identify several problems:
- The name LoadData is not descriptive of what actually goes on in the method: it performs a lot more than just ‘load the data’
- The method performs many things: what do we test?
- The method introduces dependencies on external objects
- You cannot specify the file name from the outside, you’re stuck with ‘observations.xml’
- The method is difficult to test: which part of the method do we test? If it fails, then where does it fail exactly?
Phase 1: Cleanup refactorings
Visual Studio 2012 comes with several built-in refactoring tools that come very handy. Probably the easiest thing to do is to rename the method. Go ahead and rename the method to ‘LoadAndAggregateData’. You will see a small red rectangle appear underneath the method name:

Hover above the rectangle with the mouse – or press Ctrl+’-‘ while having the cursor on the method name – and you’ll see a small context menu which allows you to rename the method. This will also rename the method where it is referenced elsewhere in the code, such as in Program.cs. If you don’t do this then you have to go through the entire project and rename the references as well. You can rename parameter names, classes, namespaces etc. the same way.
A great step towards testability is to remove the inline dependency on the ‘document’ parameter. It should be injected in the method by way of method injection known from DI – Dependency Injection. It simply means that we let the method accept a parameter instead of directly building one itself. Modify the method as follows:
public IEnumerable<Observation> LoadAndAggregateData(XDocument document)
{
List<Observation> observationList = new List<Observation>();
foreach (XElement element in document.Element("Observations").Elements())
{
double highValue = (double)element.Attribute("High");
double lowValue = (double)element.Attribute("Low");
Observation observation = new Observation();
observation.HighValue = highValue;
observation.LowValue = lowValue;
observationList.Add(observation);
}
Aggregator aggregator = new Aggregator(observationList);
IPartitioner partitioner = new DefaultPartitioner(2);
ICalculator calculator = new AveragingCalculator();
IEnumerable<Observation> observations = aggregator.Aggregate(partitioner, calculator);
return observations;
}
Now we can pass in any type of XML document, the method doesn’t need to get it from a file. This is a breaking change but has a very positive effect so we’ll keep it. The clients will need to adjust like in our case in Program.cs:
IEnumerable<Observation> observations = processor.LoadAndAggregateData(XDocument.Load("observations.xml"));
The code that reads the XML should go into a separate method so we’ll factor it out. Highlight all rows from ‘List observationList’ to the closing bracket of the foreach loop. Right-click the selection and then select Refactor, Extract Method…:
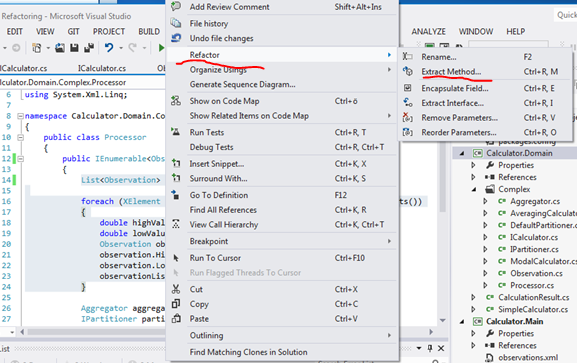
In the Extract Method window set the method name to ParseMeasurements and click OK. You should see that the highlighted code was factored out to a separate private method. You can remove the ‘static’ keyword from the method signature. The variable observationList is now built using the ParseMeasurements method.
We’ll do the same thing to the measurement aggregation bit. Highlight the rows from ‘Aggregator aggregator’ to the return statement. Extract a new method called AggregateMeasurements using the technique described above and you should come to the following code:
public IEnumerable<Observation> LoadAndAggregateData(XDocument document)
{
List<Observation> observationList = ParseMeasurements(document);
return AggregateMeasurements(observationList);
}
private IEnumerable<Observation> AggregateMeasurements(List<Observation> observationList)
{
Aggregator aggregator = new Aggregator(observationList);
IPartitioner partitioner = new DefaultPartitioner(2);
ICalculator calculator = new AveragingCalculator();
IEnumerable<Observation> observations = aggregator.Aggregate(partitioner, calculator);
return observations;
}
private List<Observation> ParseMeasurements(XDocument document)
{
List<Observation> observationList = new List<Observation>();
foreach (XElement element in document.Element("Observations").Elements())
{
double highValue = (double)element.Attribute("High");
double lowValue = (double)element.Attribute("Low");
Observation observation = new Observation();
observation.HighValue = highValue;
observation.LowValue = lowValue;
observationList.Add(observation);
}
return observationList;
}
The last immediate change we’ll introduce has to do with the value 2 in the DefaultPartitioner constructor. This value can be confusing to those who read your code. Why 2? What’s 2? What does it mean? It’s more meaningful to introduce constants. Add the following constant to the class:
private const int groupSize = 2;
…and replace ‘2’ with the ‘groupSize’ constant.
Phase 2: factoring out abstractions
The above changes were a great relief: they have brought with them a higher degree of maintainability and readability. You may well be aware of abstractions – polymorphism – in an object oriented programming language: abstract classes and interfaces. They are useful in many ways: they introduce loose coupling between classes, increase testability as you can pass in any implementation to the method under test, they help factor out common attributes of related classes and they also increase the extensibility of your classes as many different implementations can be added to the class.
Let’s see what can do to improve the Processor class. We’ll first extract an interface from the Processor implementation. This will allow us to introduce different types of Processors in the future, ones that perhaps carry out the data aggregation in a different way. It will also enable us to pass in any IProcessor object into a method under test that is expecting an IProcessor parameter in its method signature. Then the unit test will not be tied to a single implementation.
Place the cursor on ‘Processor’, right-click it, select Refactor and Extract Interface… The Extract Interface window will provide reasonable defaults so just press OK. You’ll see a new file called IProcessor.cs in the solution. Locate it and modify it slightly to include some using statements instead of the long fully qualified class definitions:
using System;
using System.Collections.Generic;
using System.Xml.Linq;
namespace Calculator.Domain.Complex
{
public interface IProcessor
{
IEnumerable<Observation> LoadAndAggregateData(XDocument document);
}
}
You’ll also see that Processor now implements IProcessor:
public class Processor : IProcessor
We’ll also introduce a base class for the Processor so that all derived classes must follow the AggregateMeasurements + ParseMeasurements setup. Add a class called ProcessorBase to the Complex folder of Calculator.Domain:
public abstract class ProcessorBase
{
public abstract IEnumerable<Observation> AggregateMeasurements(List<Observation> observationList);
public abstract List<Observation> ParseMeasurements(XDocument document);
}
Make Processor derive from ProcessorBase:
public class Processor : ProcessorBase, IProcessor
…and change the signatures of the implemented methods to the following:
public override IEnumerable<Observation> AggregateMeasurements(List<Observation> observationList)
public override List<Observation> ParseMeasurements(XDocument document)
We could continue refactoring but we’ll stop here. The purpose of the post was to show you the importance of refactoring.
In the next post we’ll start looking at a special topic within TDD: mocking. Mocking is important in order to build dependencies for the system under test. The framework we’ll use is called Moq.

