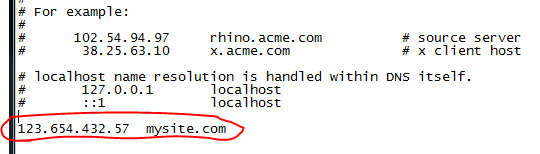
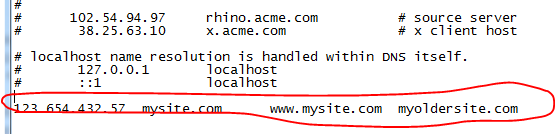
We’ll continue our discussion on basic networking we started in the previous post.
IP routing
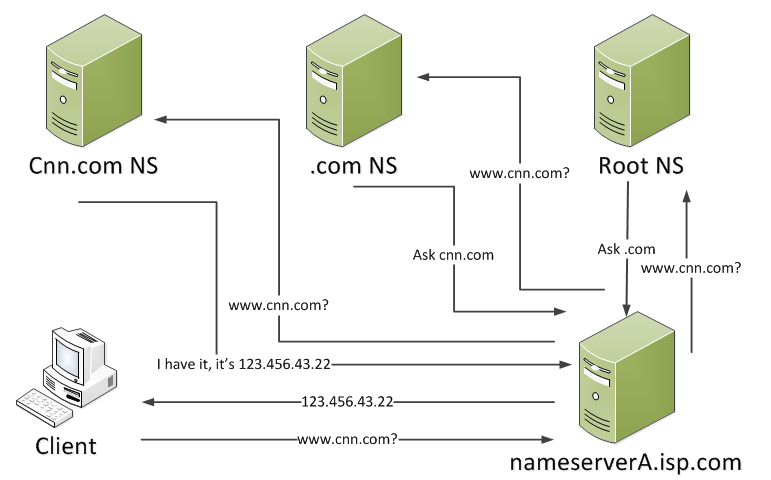
We’ll start off by looking at how traffic is routed from one network to another. Look at the following diagram:
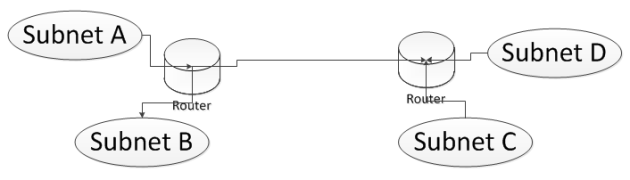
We’ll talk about subnets in a little while: it’s a collection of computers that can talk to each other without needing to go through a router. A router connects different subnets – it routes traffic between different subnets. So if a computer within subnet A wants to talk to a computer on subnet B or on subnet C then traffic will pass through one or more routers. Let’s look at a couple of tools where we can watch this IP routing.
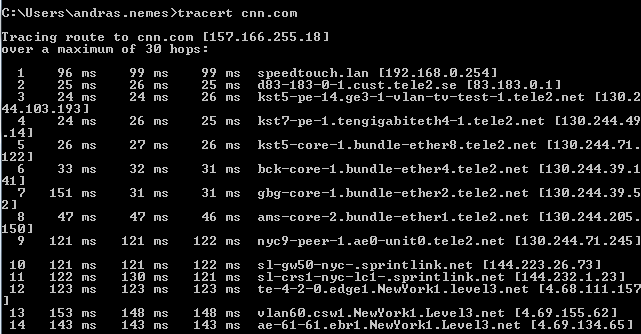
We’ll check out tracert – trace route – first which is a command line tool. Open up a command prompt and type tracert cnn.com:
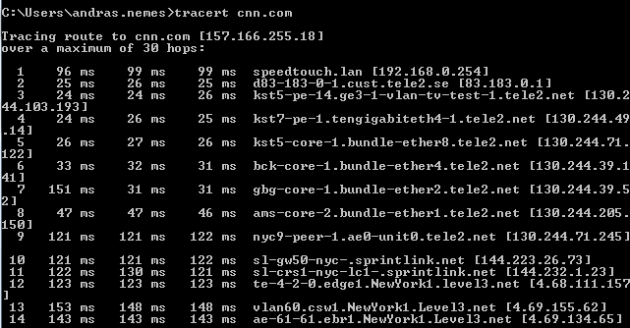
The list is a lot longer, I didn’t copy the entire output. The list shows you the routing trace, i.e. the series of routers this traffic has to pass through in order to reach cnn.com. It takes measurements to see how long each hop takes.
Note that the values you see on your machine will almost certainly look different – the routing depends on your location in the world. It would be strange for you to have the same route as me if you are located in the US whereas I’m in Sweden.
The topmost entry is typically your local router connected to your modem. Then it goes on to the routers of my ISP which is Tele2 etc. You can then even read the geographic location of some of those routers: New York, Washington, Atlanta. The trace shows all the hops the traffic needs to pass from your computer to the cnn.com web server. The second column of millisecond values shows how long each hop took. In case of routing issues these values may be very large or you may even see a timeout.
If you identify a bad link in this chain then you’ll most likely have no control over it, you’ll just have to accept the news, but it can be good to be aware of the problems. The hops will take of course more time if you want to reach a server in the US from Europe. So if you have your business in the US and expect traffic from Europe then it can be a good idea to place a couple of web servers on the East Coast of the US so that these hops take shorter.
There’s another tool called pathping which has a similar purpose but gives you a more robust report. Type pathping cnn.com in the command window. The tool will output the same routing chain as tracert but will also perform a series of tests on these links over a long period of time. It will hit every link 100 times and output some statistics. You will see something like ‘Computing statistics for 400 seconds…’ in the command prompt meaning that it will take 400 seconds to calculate the statistics. The stats may look as follows:

What’s new is the lost/sent packet ratio: in the above case there were no packets lost whatsoever. This is what we should see in a healthy connection state.
Subnets
So routers direct traffic between subnets but what are subnets? The subnet is defined by a combination of the IP address and the subnet mask. Example:
IP: 193.169.115.230
Subnet mask: 255.255.255.000
The subnet mask has the same format as an IP address, i.e. it consists of 4 octets. The first 3 octets of the subnet mask have 8 bits turned on. 255 is written as 11111111 in binary notation, i.e. 8 bits. The last octet is turned off. The octets where the bits are turned on represent the network or the subnet. Where the bits are off, that represents a specific node on the subnet. In the above example the last octet of the IP address, i.e. 230 represents a specific node in the network denoted by 193.169.115. If the subnet mask is 255.255.000.000 then the the specific node is 115.230 within the subnet 193.169.
The subnet mask can be further broken down into 4*8 = 32 bits: 255 = 11111111 in the binary system as mentioned above, so the subnet example can also be written as 11111111.11111111.11111111.00000000. Therefore we have 24 bits turned on and 8 bits turned off. We can say that the subnet can have an IP range of 193.169.115.000 to 193.169.115.255. We can denote the same thing as 193.169.115.000/24 or 193.169.115.000/255.255.255.000. You can have a single 0 in place of the triple 0’s: 255.255.255.0.
Therefore if a computer with IP of 193.169.115.124 wants to communicate with another computer with IP 193.169.115.236 then the communication is direct, i.e. not routed through a router as both computers a located within the same subnet. If the other computer lies outside of that range then it will need to go through its default router. You can see how this changes if the subnet mask is 255.255.0.0 instead, i.e. 1111111.11111111.00000000.00000000. Then the IP range of this subnet becomes 193.169.0.0 to 193.169.255.255.
The subnet mask can vary and not always look that pretty: 255.255.254.0 i.e. 11111111.11111111.11111110.00000000. So we have 8 bits on, then 8 bits on then 7 bits on and 0 bits on. This is a 23 bit subnet which changes the IP range to 193.169.115.0 to 193.169.116.255. So you would normally think that the ranges are parts of different subnets, but you have to look at the subnet mask to be able to tell for sure.
Another example: with a subnet mask of 255.255.255.240 we have 28 bit subnet, i.e. 11111111.11111111.11111111.11110000. This is saying that we’ve broken down a ‘clean’ subnet into smaller pieces. The IP range will then span between 193.169.115.124 and 193.169.115.139. This is an extremely small subnet.
Route tables
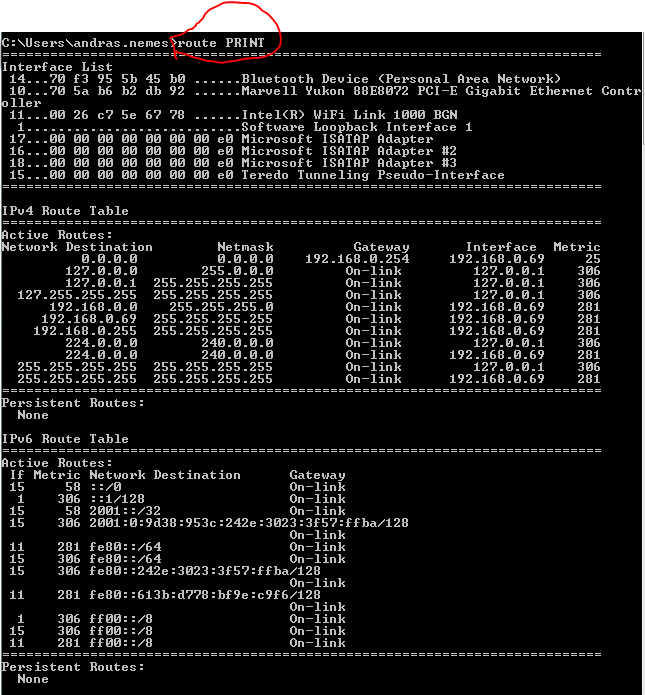
How does the computer determine how to reach other subnets? This is where route tables enter the picture. Open a command prompt and enter the route PRINT command:
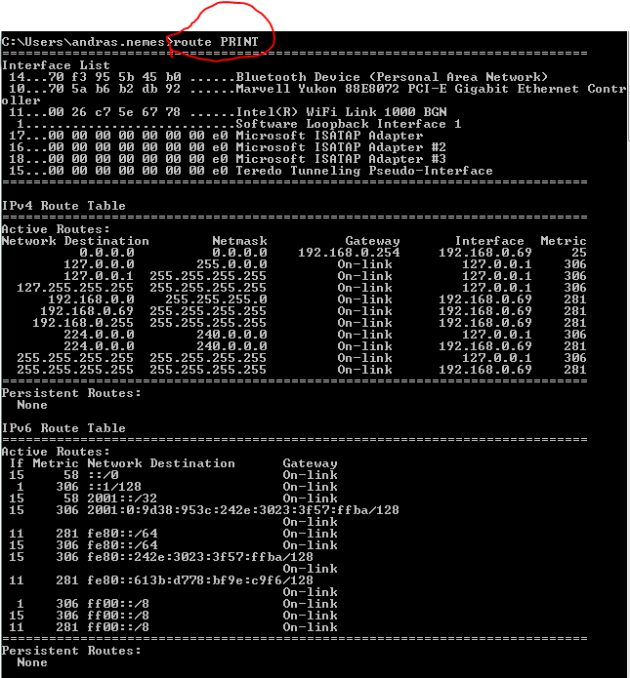
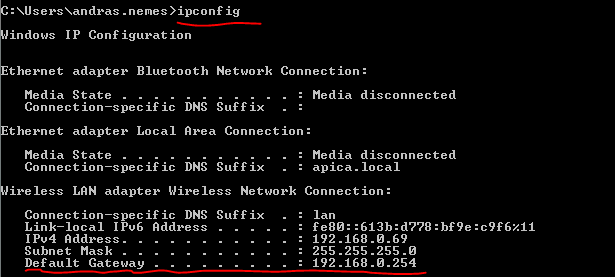
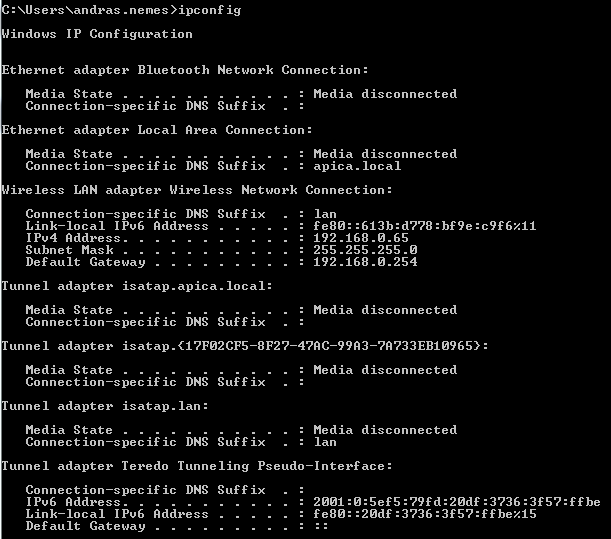
Locate the first entry in the IPv4 route table with a network destination and subnet mask of 0.0.0.0 which means any IP address. The gateway the traffic needs to go through will be 192.168.0.254 on the interface 192.168.0.69 which is my current private IP address. The last value is the metric where the lowest value has priority so the gateway with the lowest metric will be the default one. The ‘on-link’ values are special: they denote your own computer so there’s no need for routing in those cases. E.g. all 127.x.x.x addresses point to your local machine, i.e. the localhost. Your computer will know the Gateway through the IP configuration:
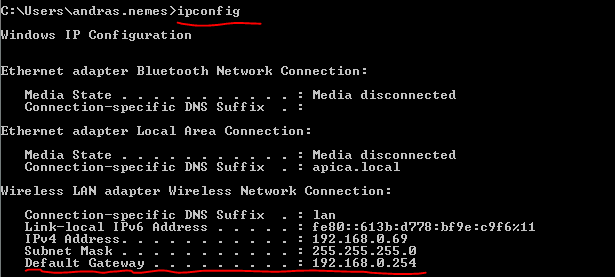
Any traffic that’s destined to another network goes through this default gateway.
Network address translation (NAT)
You may have spotted the term ‘private IP’ in the previous section. There are 3 network ranges that are for private use only in IPv4: they cannot be routed to in the public internet. You typically get one public IP address from your Internet Service Provider but you can have several machines online at home: your PC, your desktop, your phone and possibly others. They each will use a private IP. IPconfig returned my private IP address under ‘IPv4 Address’.
A mechanism called Network address translation takes these private private IPs as they leave my home and converts them into the external public IP. It also translates the incoming public IP to the correct private IP address.
As private IPs are not reachable from the Internet it’s obvious that if you want to host a site available on the public Internet then you need a public IP address. You can actually host your website on your desktop at home by declaring that all traffic to your public IP address on port 80 – which standard HTTP traffic goes through – be routed to one specific private IP, in this case the private IP of your desktop. So you cannot direct port 80 traffic to more than one private IP.
The following ranges are for private use only:
- 10.0.0.0 with a subnet mask of 255.0.0.0
- 172.16.0.0 with a subnet mask of 255.240.0.0
- 192.168.0.0 with a subnet mask of 255.255.0.0
You’ll recognise that the private IP I mentioned above fits in the the last range. The value you see in ipconfig on your machine will most certainly fit in one of these ranges.’
Ports
Ports are used to connect to a process on the server side by some protocol. The process will be listening to incoming messages on a certain port. HTTP websites listen to port 80 and HTTPS websites on port 443 by default. Many message-based products will listen on some default port: Apache Tomcat on port 8080, MongoDb on 27017, SQL server on 1433. The most common transport layer protocol is TCP which stands for Translation Control Protocol. Almost all web traffic – HTTP, mail – runs on TCP.
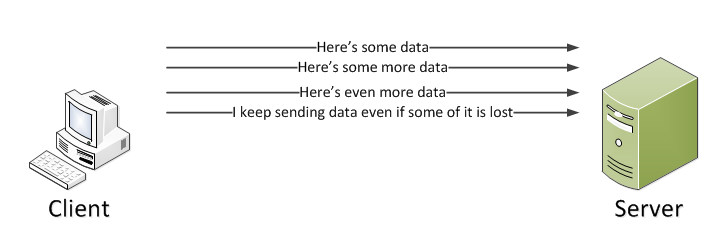
The sender, i.e. the client computer, wants to establish a session with the receiver, i.e. the server. The receiver will establish that session and declare that it’s ready to accept data. The client will then send one or more data sets. The server then sends a messaging confirming which messages it received. It’s possible that one or more data sets the client sends out is lost. In that case after a timeout period the lost data set will be resent. The server will confirm in case it received that message. The sender will know that the receiver has received the entire data pack:
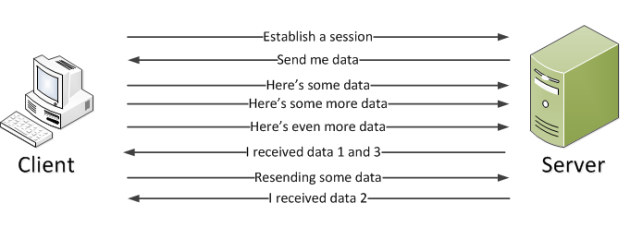
The messaging process is managed by the networking stack. You don’t need to prepare anything extra in your application on the server side to accommodate the process.
TCP is not the only transport protocol type: UDP or User Datagram Protocol is another example. In UDP the sender doesn’t establish a session first. Instead, it starts sending data right away. Here there’s no built-in mechanism to resend lost data packets. So if some data set is lost then it cannot be resent:

UDP can be a good choice if losing some data packets is acceptable, e.g. in the case of video conferencing. If let’s say the 5th second of the video is lost and the participants keep talking then in the case of TCP the 5th second would be resent interrupting the flow of the video. Also, there’s no session involved in UDP meaning it has a lower overhead. However, in most messaging scenarios on the internet we do care about data and we need all data in order to process the requests. In that case TCP is the preferred choice.
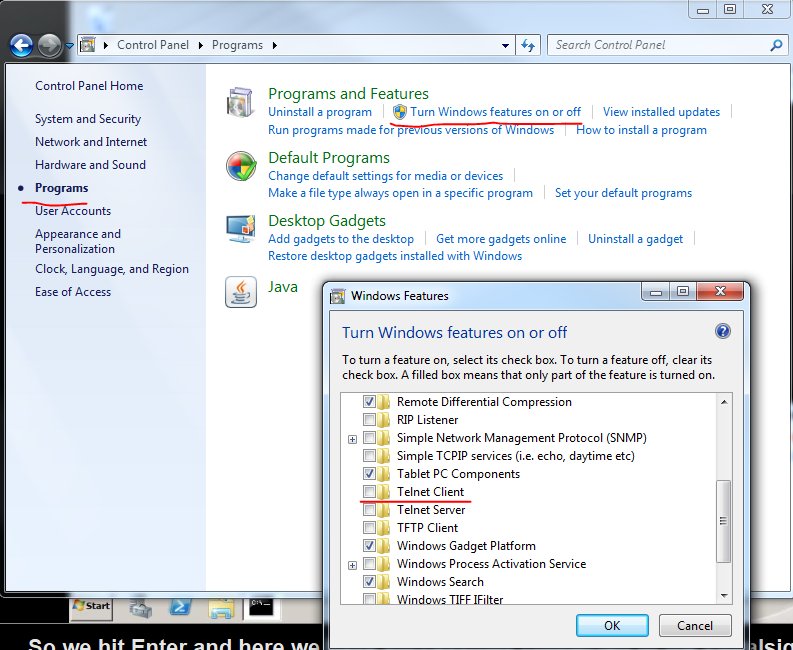
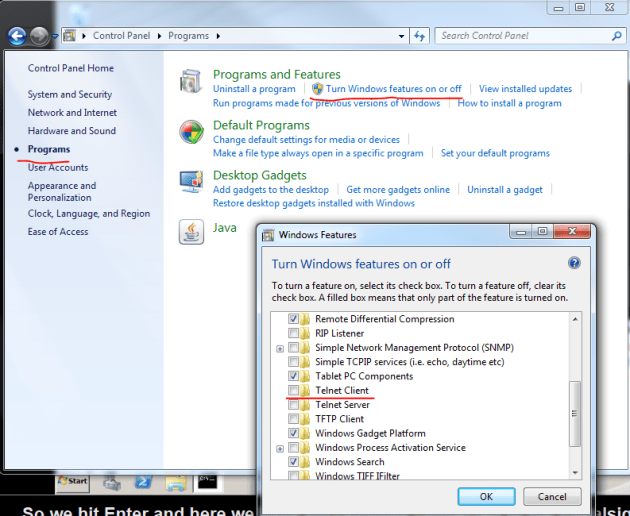
You can test port connectivity using the command line using the telnet command. You can only test the TCP protocol this way. With UDP we simply send data and hope that it arrives. With the telnet command you can establish a session and send the commands to the receiving application, much like a web browser would do. Open a command prompt and type ‘telnet microsoft.com 80’: we want to connect to the process microsoft.com on port 80 which is the standard port for HTTP traffic. In case the command prompt is complaining about telnet not being an available command you need to turn on that feature:
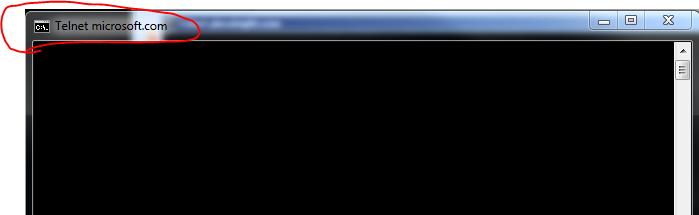
The command prompt should go all black upon a successful session setup:

The microsoft.com server assumes that it has established a session with a browser and is ready to accept data. We could send HTTP GET requests to the server and expect some answer in return. Press Ctrl+C and enter to exit and you’ll see that the server has sent a 400 Bad Request:
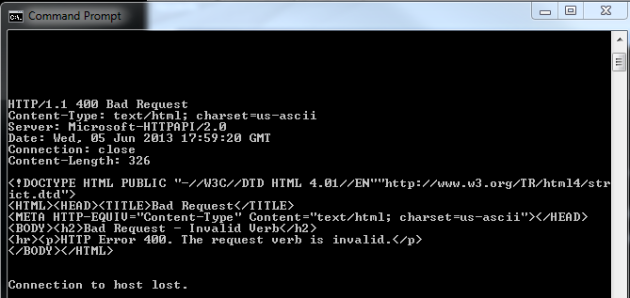
The server didn’t understand what we wanted so it returned a HTTP 400. It even sent back some HTML that a web browser can render. We have successfully connected to an IIS process!
Now try to connect to port 81: type telnet microsoft.com 81 in the command prompt. There’s probably no process listening on port 81 on that web server but let’s see what happens:

The networking stack of the operating system is trying to establish a connection by sending out a session request to port 81 on microsoft.com. It’s possible that there’s some process listening on this port but the firewall is not letting through the request. Eventually we get the timeout message as seen above.
It’s not only HTTP websites that you can connect to of course using telnet but any type of process listening on some port. If you know that there’s an SQL server process on computer Machine01 then you could connect to that process and issue SQL commands by typing ‘telnet Machine01 1433’, where 1433 is the standard port SQL servers is expecting commands on.
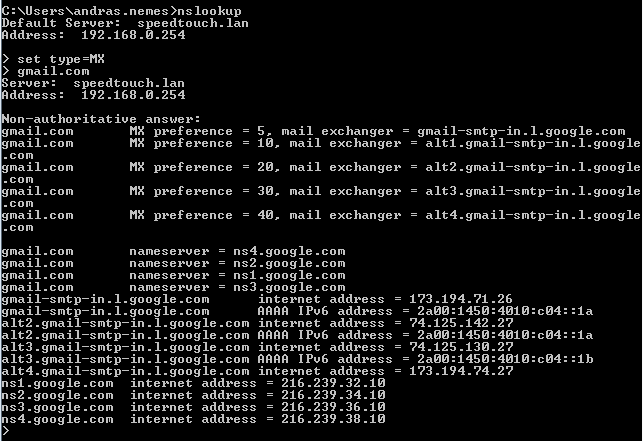
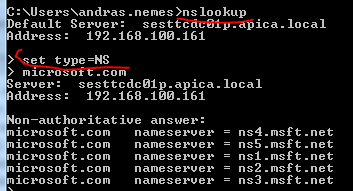
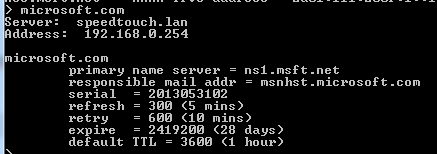
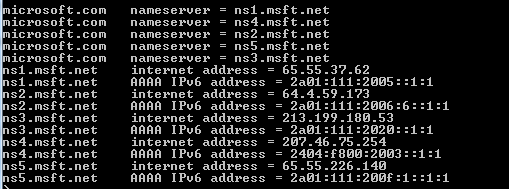
Let’s now see how a mail server process responds. Let’s find the mail server name of gmail.com using nslookup:
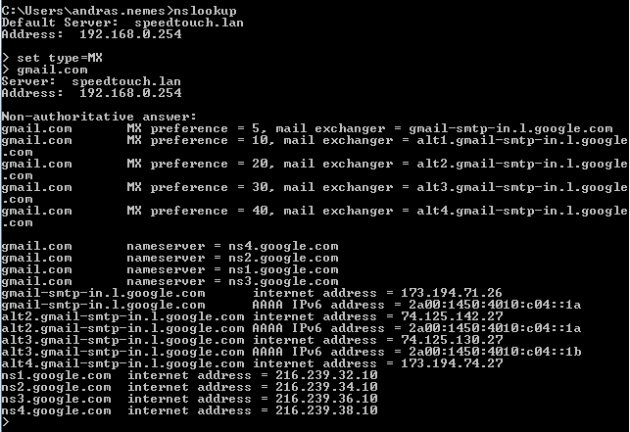
Let’s try the one with the lowest preference value: gmail-smtp-in.l.google.com. SMTP mail traffic normally listens on port 25, so let’s issue the following telnet command: telnet gmail-smtp-in.l.google.com 25. If you successfully connect to the mail server then you should get a banner that says something like ‘220 mx.google.com ESMTP xxxx.79’. You can then send emailing commands to that port if you want to. You can quit the process by typing ‘quit’.
So you can use telnet if you know the port number to connect to. If you’re not sure then you can port scan the server using the the free nmap utility available here. Download the appropriate Windows installer and install the tool. Then you can issue the ‘nmap -v [machinename]’ command for a verbose port scan. The tool will try to connect to various TCP ports and list the ones where it was able to get through.
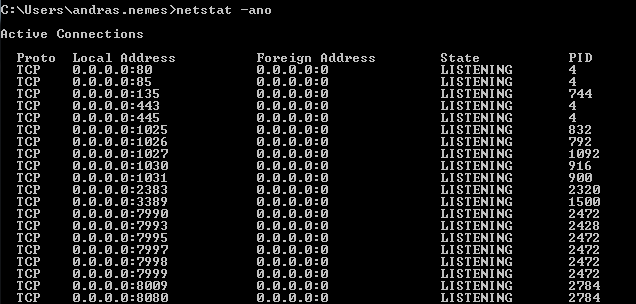
If you want to see which ports your computer is listening on then issue the ‘netstat -ano’ command:
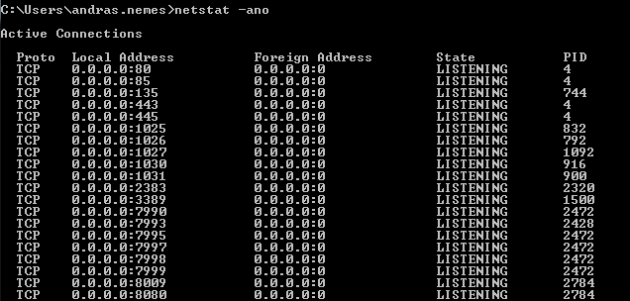
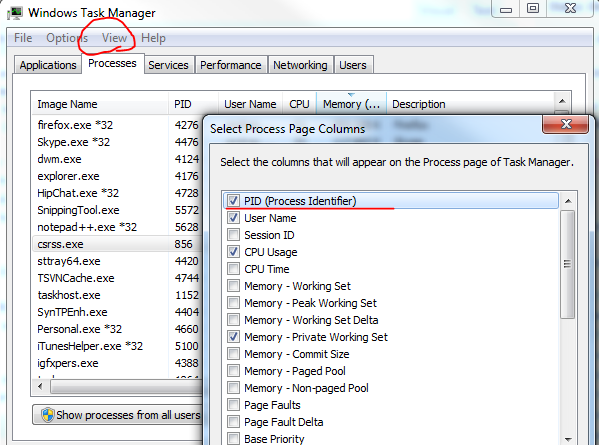
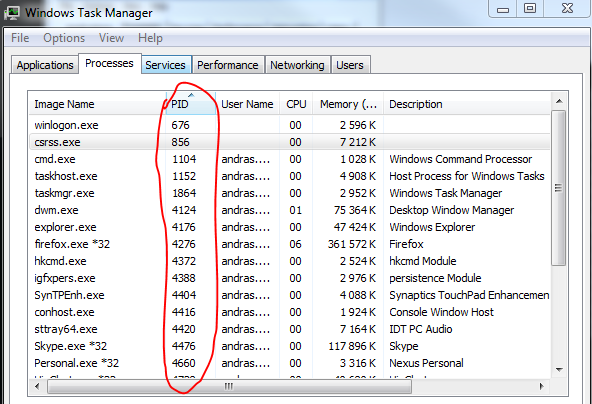
The image shows only an extract of the full list of processes. 0.0.0.0 means that it’s going to listen on every IP address that’s available on the localhost. The port numbers are appended to the IP, e.g. :80, :443 etc. You’ll see the PID column on the right hand side. This shows the ID of the process or application that’s communicating with the process on that port. Open the task manager and add the PID column to the window:
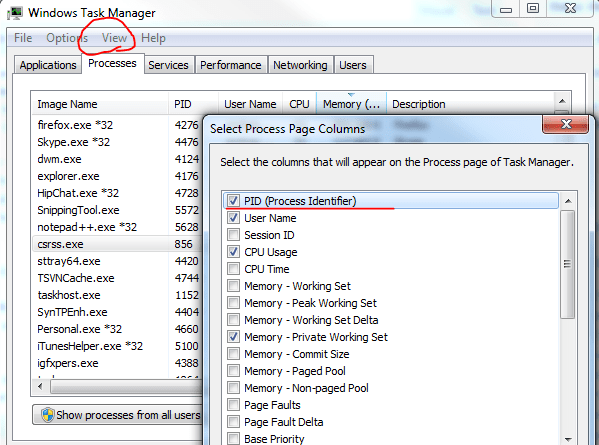
You can then try and locate the process with some ID:
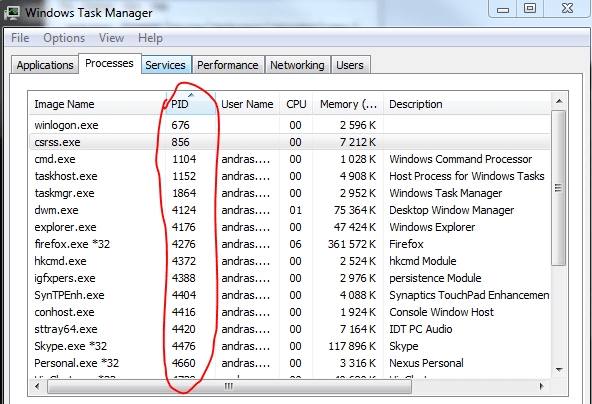
This is helpful if you want to find a specific process using a port. Also, it helps finding conflicts when 2 or more processes are trying to listen on the same port.