Web farms in .NET and IIS part 3: Application Request Routing ARR
June 24, 2013 17 Comments
Introduction
In this post we’ll look at the basics of Application Request Routing. The target audience is beginners who have not worked with ARR before and want to get going with it.
As mentioned in the first post of this series ARR is an extension that can be added to IIS 7.0 and above.
ARR has a lot more available functions than Network Load Balancing (NLB) making it the better load balancing option. However, ARR doesn’t have its own solution for high availability so it cannot handle failures to the server hosting ARR – the result is that the ARR server becomes a single point of failure. This is where NLB enters the scene as it provides high availability – ARR and NLB together make up a very good team.
ARR comes with the following advantages compared to full-blown hardware based load balancers:
- Cost: if you have IIS7.0 or above you can install ARR free of charge
- Ease of use: this is of course relative, but if you have some basic knowledge of IIS then the learning curve will be minimal
- Performance: ARR can handle very large sites with ease – the first resource limit that ARR runs into is network. Most networks support 1 Gbps or more, so this is usually not an issue
- Flexibility: ARR offers load balancing based on any server variable, URL, cookie etc.
ARR has some disadvantages:
- As mentioned above ARR doesn’t have its own built-in solution for high availability
- It does not offer the same range of features as more complete hardware based products. E.g. it lacks SEO treatment and DDoS handling. Some of these shortcomings can be solved with other products, such as NLB or Request Filtering
You can get pretty far with NLB and ARR unless you have some very specialised needs that only expensive commercial products can provide.
ARR is a software based reverse proxy solution – for an explanation of these terms check out the first post in this series. It supports all common load-balancing algorithms, such as server weighting, round-robin etc. The following general list shows the features available in ARR:
- Health checking
- Caching
- Can work as a Content Delivery Network (CDN)
- SSL offloading
- HTTP compression
- URL rewrite
- Usage reporting
- Sticky sessions
- Programming and automation support
ARR only handles HTTP traffic, so it cannot work in conjunction with FTP, RDP etc.
Routing
ARR routing goes through three touchpoints:
- IIS site binding: your website will of course need to have a valid URL which we can call the ARR base. It is a site that appears below the Sites node in the IIS manager
- URL rewrite rule: this happens at the IIS level
- The server farm
When a web request hits the ARR server it is first caught by the IIS binding. A standard binding needs to exist on a website. This is the same process as setting up a new website in IIS under the Sites node. It can be a generic website with no real content – it is only used for the HTTP and HTTPS bindings. Also, it is here where SSL offloading occurs.
The request is then caught by URL Rewrite as long as an appropriate rule exists. This happens at the PreBeginRequest step in the IIS pipeline so it is performed before any other site functionality. URL Rewrite rules can edit server variables as well.
In the last step the server farm gets the request from URL Rewrite. It determines which server to send the request to based on the load balancing algorithm and client affinity settings.
How-to
You can download ARR on your designated routing server using the web platform installer available here. Search for Application Request Routing in the search window of the installer and select the below version:

By the time you read this post there may of course be a new version of the extension.
Click Add and Install in the installer window. The installer will fetch all the dependencies as well.
As in the case of Network Load Balancer I don’t have a private network of Windows servers. Therefore I can show you the steps you need to take in order to create a web farm but will not actually create one in the process.
As soon as you install ARR you will see a new node called Server Farms in the IIS manager:

Right click on that node and select Create Server Farm. The Create Server Farm window will appear where you can add the Server farm name:

You can provide any name here, like in the case of the, but give it some URL-type of name, such as arr.mysite.com. It’s a good idea to provide the same name as the URL for the ARR version of your website. Example: if your website is http://www.fantasticsite.com then the ARR version may well be arr.fantasticsite.com. Click Next to go to the Add Server window:

Here you can add the servers that are the members of the farm. Add the server address one by one in the Server Address textbox and click Add after each entry. The servers you will appear in the list box. Click Finish when you’re done with this step. ARR will then ask you if you want to create any URL rewrite rules:
Click yes. You’ll see that the server farm will appear in the Server Farms list of the IIS manager. Open the Server Farms node, select the name of the farm you’ve just created and you will see some additional setup options:

The default options are sufficient to test the network. Open a web browser and navigate to the ARR name of your website such as arr.mysite.com. The request should be routed to one of the web farm members you specified during the setup.
Let’s look at some of the options in the IIS manager. Clicking on Caching will open the following window:

The default setting is that anything that goes through ARR will be cached for 60 seconds and disk cache is enabled. So if 2 web requests ask for the same resource within a minute ARR will hand back the cached version to the second request without consulting the web tier. You can even set whether the caching mechanism should cache the results by the query string or not. Example: arr.mysite.com?arg=1 and arr.mysite.com?arg=2 will probably return different results from your backend database so it’s a good idea to cache by the query string.
So what is cached? ARR follows the caching rules set out in RFC2616. By default all static content such as css, js etc. is cached.
If your site streams media then checking the Enable request consolidation checkbox can be a good idea. It will consolidate all the streaming requests to reduce the number of requests.
Also, it is recommended to turn off the idle time setting of the application pool:

By default this value is set to 20 minutes. This means that the application pool will enter “sleep” mode if it sits idle, i.e. receives no web request for 20 minutes. Set that value to 0 to turn off this feature, which is recommended anyway, so not only in web farm scenarios. This keeps your site actively running while maintaining the health checking even during quiet times.
ARR can even function as a Content Delivery Network to front entire web farms. Check out the resources on this page for a video user guide.
The Health Test window looks as follows:
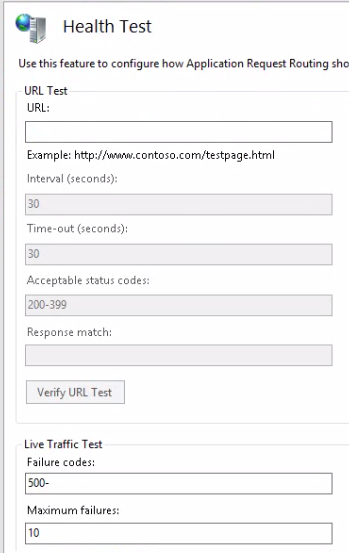
Here you can schedule explicit health checks and/or rely on live traffic tests. Live traffic testing watches for errors with the live traffic. If it sees what you define as a failure it marks that server as unhealthy. The main advantage of this method is that is watches for errors with any type of page request not just a single testing URL. The main disadvantage is that if the developers release a bad, untested version of the website then eventually all web farm machines may be turned off as all of them may eventually produce the same error if the same page is requested by the clients. This makes a DoS attack a breeze and even completely innocent clients can break down your site if they hit F5 often enough. Also, if a live traffic test shuts off a web server then that server is not brought back online automatically. Therefore it’s very important that you set up explicit URL testing as well and don’t rely on live tests exclusively.
You can configure live traffic tests as follows:
- A comma separated list of failure codes that will cause the web server to be marked as unhealthy. You can even define a range with a hyphen, e.g. 400-500, or mix the styles such as 500, 510-599
- The number of maximum failures that must occur during the failover period before the server is marked unhealthy
- The failover period in seconds is used along with the maximum failures to determine if there are too many failures during the failover period. If this value is set to 0 then live traffic testing is disabled.
With explicit URL testing you ask ARR to send a request to the web farm members with specific time intervals and inspect the response. You can provide the URL in the URL text box. The test request will be sent to each machine in the farm. It’s highly recommended that you set up explicit URL checks so that unhealthy servers are not allocated any web requests. You can enable explicit URL tests by providing a URL in the appropriate text box. We’ll come back to this type of test a little later, but here are the parameters you can set:
- The test URL whose response is inspected by ARR
- The time between tests in seconds – if the test fails ARR will continue to send the same request and bring the server back online if the test passes
- The timeout in seconds before the health test gives up on a page that takes too long. If ARR receives no response before the timeout then the server is marked as unhealthy.
- The Acceptable status codes field works the same way as failure codes in the case of live traffic tests
- You can also perform a content match to ensure that a certain word or phrase can be found on the page.
Bear in mind that ARR will mark the server as unhealthy after the very first bad response. Therefore make sure that the testing interval is not too long as even fully functioning and healthy servers may produce bad responses from time to time.
In the bottom of the same window you’ll see another text box where you can define the number of minimum servers. The idea here is that if you know that you need a certain number of healthy servers to reasonably handle the load then the health test shouldn’t allow the server farm to drop below that level. Example: your web farm has 10 machines and you need a minimum of 6 to handle the load on an average day. If the number of healthy servers drops to 5 then it may be a better idea to bring all machines back online again: 5 out of 10 users will receive good experience, so not all visitors will be impacted. The quality level is difficult to predict: your users may see intermittent errors that only occur if their request is directed to one of the bad servers. This is a tradeoff: the web farm will not be rendered completely useless due to overloading but the user experience may not be top class either. If this limit is reached then ARR will ignore all scheduled tests and bring back all servers online again.
The test URL should be a very simple self-contained page: it should not access the database or your application logic. If your database or application layer fails then all the web farm machines will be taken out of action. The ideal test page contains only some static HTML. Make sure that the test page only fails if there’s a problem with the specific server the page is employed on. Otherwise, if the test page fails on every server then the entire web farm will be useless as all servers are brought offline.
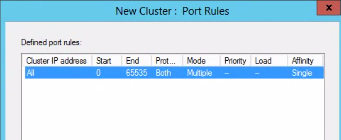
You can pick the load balance algorithm in the Load Balance window, meaning how would like to set the rules for web request routing:

The default option is Least current request which is probably the most logical choice. This option means that the web request will be routed to the web farm member that has the least amount of request. Weighted round robin tells ARR to route the requests to each web farm member in turn: first to server 1, then 2 then 3, back to 1, then 2, then 3 etc. regardless of the current load each machine. You can find the explanation of each algorithm in the first post of this series.
If you change the default options you’ll need to select Apply to the right:
The Monitoring and Management window will show you the web request statistics and current health state of each member of the web farm:

You can even get some real time disk cache statistics in the bottom of this window:

Proxy allows us to configure how the packets are forwarded:
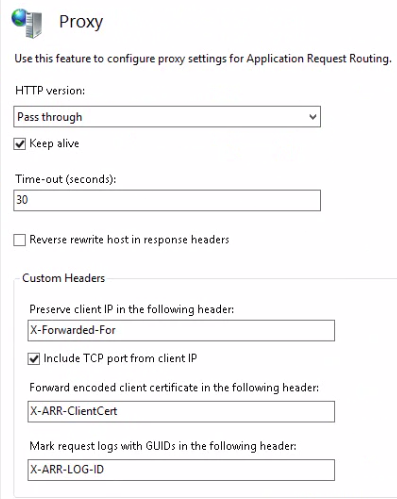
Preserving the X-Forwarded-For header can be useful if you want to see which IP the client’s request originated from.
In the Routing Rules window we can set various advanced features.

You can e.g. let the ARR server take care of SSL encryption and decryption by selecting the Enable SSL offloading option which is set by default. Keep in mind that ARR is a reverse proxy load balancer meaning that the web farm servers will see the http request coming from ARR and not from the client. If ARR is responsible to encrypt and decrypt SSL then the web farm will get HTTP requests from ARR even if the original request was sent through HTTPS. If it is critical in your environment that the web farm receives HTTPS requests then a tool called ARR Helper can be something to consider: it digs out the details of the original HTTPS message from the ARR server and writes them back to the original locations thereby fooling the web servers into thinking that the request came from the client in the form of HTTPS. The tool can be downloaded from this link. It comes in two versions: 32bit and 64bit. The tool must be installed on the web servers, not on the ARR machine.
In the Server Affinity window you can set whether you want sticky sessions or not.

The default setting is that there are no sticky sessions. Selecting Client affinity means that the same user will be directed to the same machine during the web session. Session stickiness will be cookie based, you can even set the name of the cookie in the Cookie name text box.
With the web farm and the load balancer in place you can test how ARR behaves if one of the web farm servers is taken out of action. Go to the IIS manager of a server and stop the application pool of the website deployed there:

If you selected the round robin routing algorithm then you will see the following: a normal 200 response from the web server still up and running followed by a 503 from the one you’ve just shut down, then back to healthy server, then again to the inactive one etc. We can set up a status check to avoid this behaviour so that ARR can determine if a web server is healthy before routing any web requests to it.
Go back to ARR and select the Health checks option. Enter a URL which ARR can send requests to. It can be a page dedicated to the health checks, a very simple page with no value to a “real” visitor. Its only reason to exist is to check the state of the web server. How you implement such a logic is up to you, e.g. check if the page can connect to a web service. The outcome of that logic should be a simple boolean value: is this web server in a healthy state or not.
Then you can set the interval for the health checks in seconds:

Note that these checks are real web requests so it creates some additional load on your web site. Therefore make the status URL as lightweight as possible.
Then you can set the upper limit of the response timeout and the acceptable status codes as well. The response match text box has the following purpose: say that your status page writes a specific string in the response if the status is fine, such as “True” or “Success”. You can put that string in this text box. If the response from the status page is different from this string then the machine is deemed unhealthy.
You can test the status response by pressing the Verify URL test button:

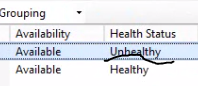
If you again turn off the application pool of one of the farm members then you should see that ARR does not route any traffic to that server. Also, the Monitoring and Management window should tell you that the server is not healthy:
High availability for ARR
As mentioned before ARR doesn’t have any built-in high availability feature. If the ARR server is down then the web farm will be unavailable. This doesn’t sound too convincing as one of the reasons we set up web farms is to ensure high availability, right? One solution is to go for a full-blown hardware based commercial load balancer but those typically cost a lot of money. If you are looking for a cheaper alternative then Network Load Balancing (NLB) can be useful. NLB is a load balancer with limited capabilities but can be used together with ARR. NLB must be installed and configured on the web servers of the farm. See the previous post on NLB.
This concludes our discussion on the basics of ARR.